MEGAZONEブログ

Deliver new business insights with SAP data
SAPデータを活用した新たなビジネスインサイトを提供
Pulisher : Cloud Technology Center ペク・ソジョン
Description:SAPデータに基づいてデータレイクを構築する方法について紹介したセッション
はじめに
最近、顧客企業のプロジェクトを進める中で、顧客企業のSAPデータに対するニーズが高まっていることを知りました。組織内の購買、会計などのtransactional dataを分析してインサイトを得たいと考えているのですが、今回のリインベントでSAPデータを基盤にデータレイクを構築するセッションがあり、申し込みました。
セッションの概要紹介

SAPを使用している方は、データが速いスピードで増え、このようなデータをどのように活用できるのかについて悩んでいることでしょう。 SAPデータをNon-SAPと組み合わせてビジネスに必要なインサイトを得ることは非常に重要です。
Nongshimの事例では、サプライチェーンの原材料需要予測のエラー率を下げるために、SAPデータをAWSで分析し始めました。AWSでSAPデータを分析し、関連するインサイトを基に予測精度を高め、在庫管理やサプライチェーンの効率を向上させました。
講演者の経験によると、リテール会社勤務時代にSAPデータが増えすぎてストレージ容量に達し、データを外部ストレージに集めてインサイトを得たいというニーズが生じたそうです。SAPデータをS3とRedshiftにロードし、SAPとNon-SAPデータを組み合わせて様々なインサイトを導き出したことを共有しました。
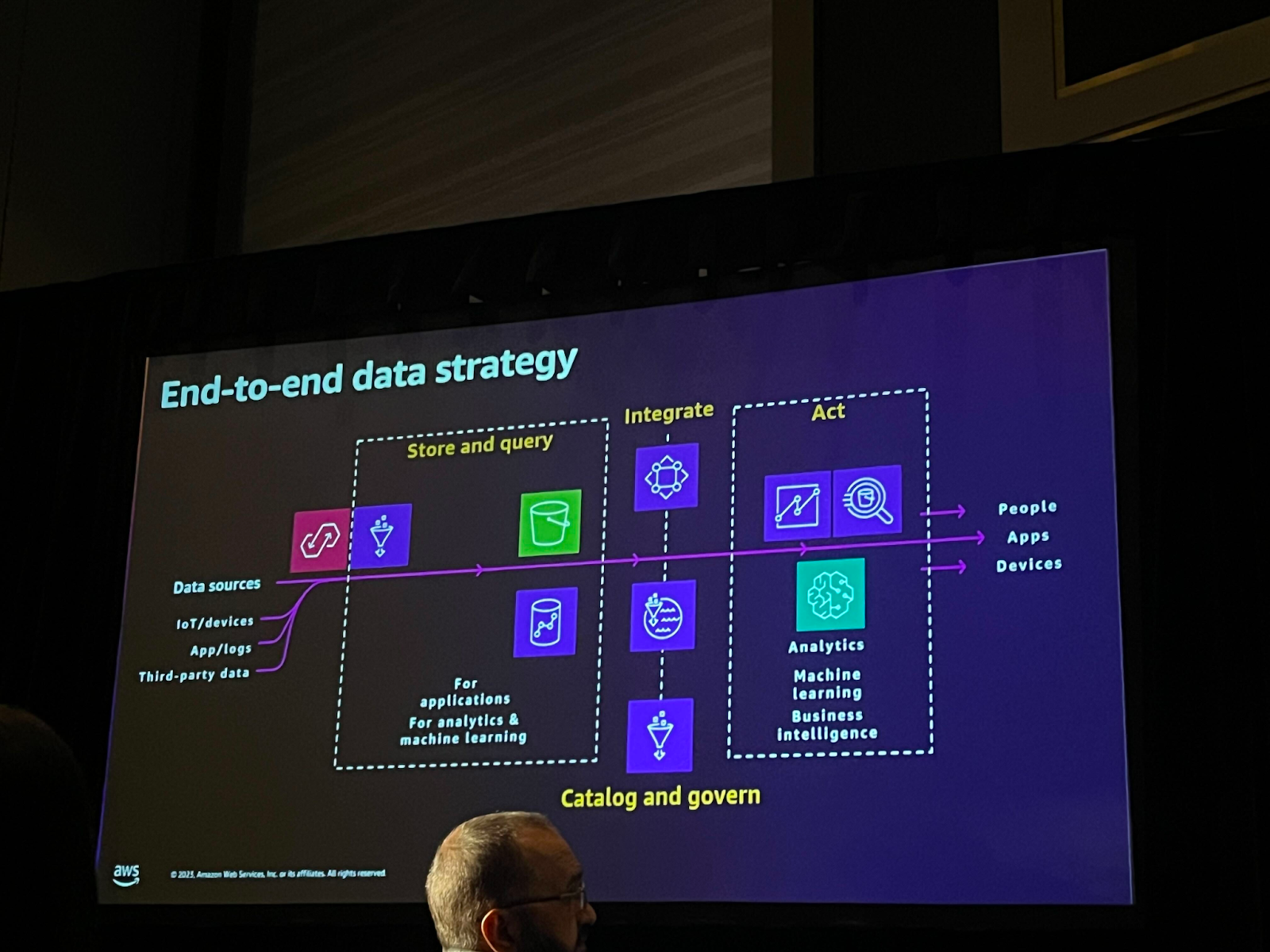
SAPデータを活用する上で重要なのは、データの活用方法だけでなく、データの一元化であることを強調しました。 また、データパイプラインの段階別に使用できる様々なサービスについて、聴衆の経験と使用したサービスを一緒にリストアップしました。 私たちが黒板にまとめた内容は以下の通りです。
・Ingest: AWS Native(Glue, Appflow), Sap Native
・Stored query:AWS Native(S3, Redshift), 3rd party(Snowflake, Teradata, Databricks), Sap Native(Datasphere, BW on HANA)
・出力:3rd party(Tableu, Powerbi), AWS Native(QuickSight, Sagemaker, Athena)
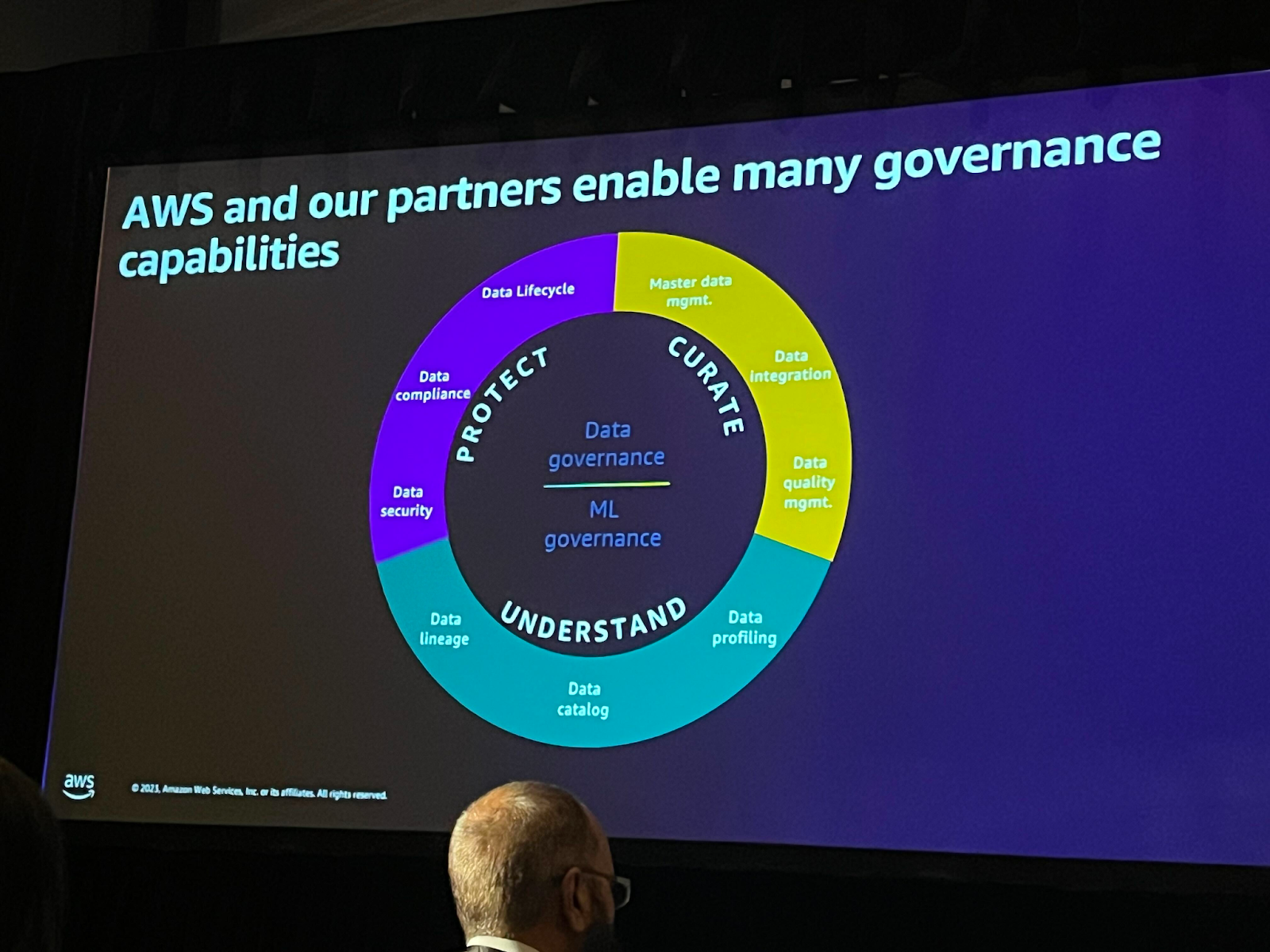
データのガバナンスをしっかり守ることも非常に重要です。AWSでも様々なガバナンス関連サービスを活用することができます。LakeFormation、DataZoneおよびGlueのData Qualityなどを適用することができます。
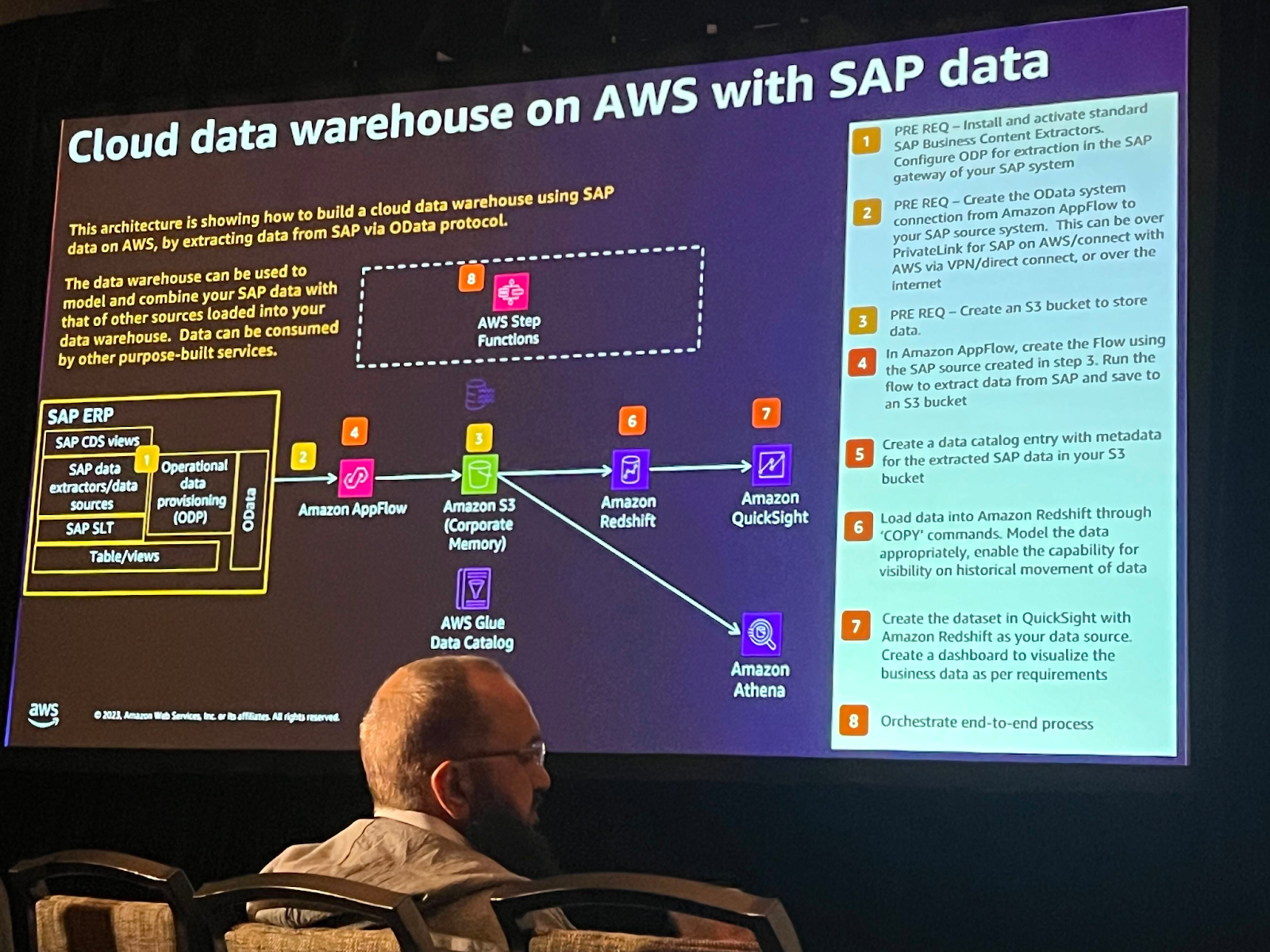
このアーキテクチャはある顧客のSAPデータパイプラインです。Odataプロトコルでデータを抽出してクラウドDWを構築するのですが、AppFlowでデータを移管した後、S3にロードされたデータをカタログ化し、分析や可視化まで行いました。
必ずしもAppFlowではなく、様々な方法でデータをingestすることができます。 また、このアーキテクチャはS3とRedshiftをメインでBatch layerに使用しますが、様々なサードパーティソリューションでデータ消費が可能です。
また、AWS Analytics Fabric for SAPを活用すれば、AWSが提供するCloudFormationスタックを通じてSAPデータパイプライン構築のための基本リソースを簡単に生成することもできます。
セッションを終えて
このChalk Talkセッションを通じて、SAPデータをAWS上で活用する方法について簡単に知ることができました。 今後もSAPデータ分析に対するニーズが増えると予想されるため、SAPデータを活用する様々なユースケースにもっと接することができるように学習が必要だと思われます。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner