MEGAZONEブログ

Best practice for querying vector data for gen AI apps in PostgreSQL
PostgreSQLでAIアプリケーションのベクトルデータをクエリするためのベストプラクティス
Pulisher : AI & Data Analytics Center チェ・スンヒョン
Description : Vector検索に対するベストプラクティスとPostgreSQLでVectorDBを構成する方法を紹介したセッション
はじめに
最近、Gen AIが様々な側面で活用されるようになり、高精度の中心となるVectorについて、どのように構成して活用するのか気になり、セッションを申し込みました。 また、身近なデータベースであるPostgreSQLでどのようにVector DBを構成するのか確認したいと思いました。
セッションの概要紹介
Gen AIの概略的な紹介とGen AIでDatabaseがしている役割についての説明から始まりました。 Vector DBとしてPostgreSQLが使われる理由とその中のpgvectorモジュールについての説明でセッションが構成されていました。

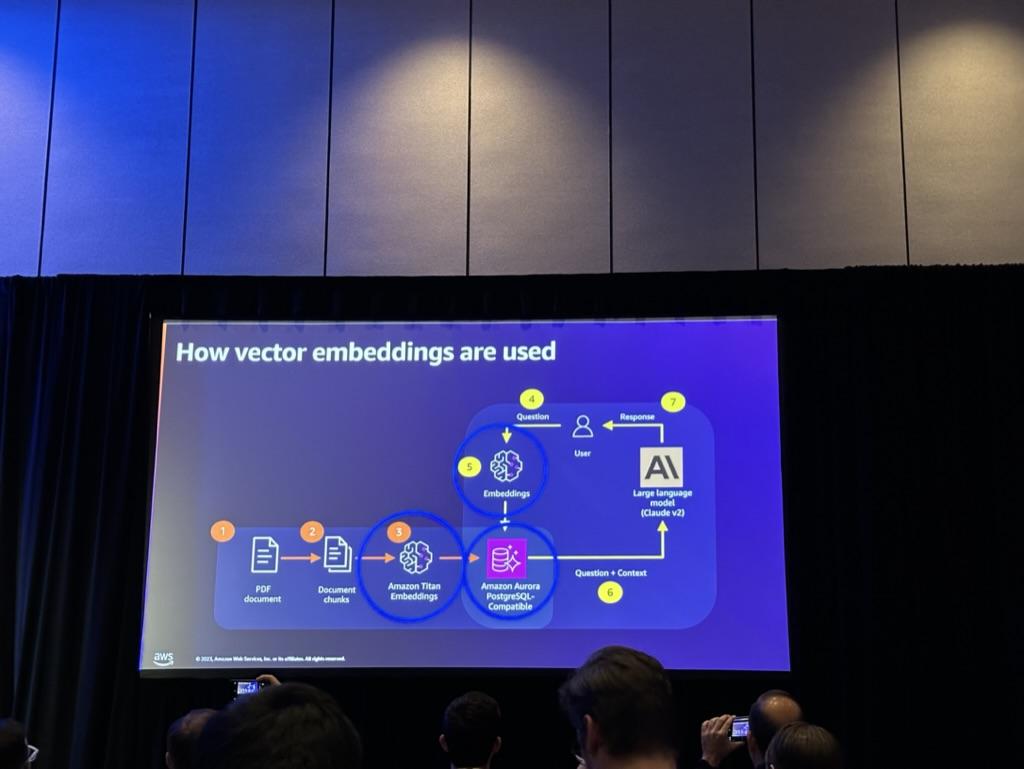
PDF文書が入力されると、これをチャンキングしてTitanに埋め込むことになります。その後、これをAurora PostgreSQLにベクトル化して保存し、ユーザーから質問が来たら、そのDBで検索して質問に合う答えを回答として送る構造で構成されています。ワークロードだけ見ると複雑ではありませんが、答えがReal-timeで出なければならないので、このVector DBをどのように構成するかがその速度に多くの影響を与えます。

そのため、Vectorを構成するためには、いくつかの注意しなければならないコンポーネントがあります。
まず、回答が来るまでの時間がとても重要です。二つ目は、データが多いため、サイズが小さくても累積されると膨大なサイズになるのでembedding sizeが重要です。第三に、すべてのDimensionをクエリしなければならないので、クエリ所要時間が重要です。

このような特徴から、Vectorストレージを選択するためには、いくつかの確認が必要です。
1.自分のビジネスワークフローの中で、どのVectorストレージが適しているか?
2.自分が持っているデータの量はどれくらいか?
3.ストレージ、パフォーマンス、コストのうち、どのような問題を抱えているか?
4.インデックス作成、クエリ所要時間、スキーマ設計など、どのようなことを諦めることができるか?
上記の要素を考慮して適切なストレージの選択が必要です。


大容量データ処理のためにPostgreSQLが持っているTOAST技術があります。
The Oversized-Attribute Storage Techniqueの頭文字を取った用語で、行を圧縮して保存したり、データを物理的な行に分割して圧縮します。データが通常2KBより大きい場合に行圧縮を先に試みます。
そして、列を保存するために4つの戦略を使用します。
1.Plain : Toastができないデータ型に対して使われる戦略です。
2.Extended : Tostが可能なデータ型に対して基本的に使われる戦略で、圧縮と外部保存の両方を許可します。
3.External : 外部保存はしますが、圧縮は許可しない戦略で、文字列に対する作業が速くなります。
4.Main : 列に対する圧縮を試み、圧縮された行が一つの行として存在できない場合、TOASTで圧縮されます。

セッションを終えて
今年度のre:Inventで最も多く言及されたGenAI関連で聞いた最初のセッションでした。ストレージ、コンピューティング、そしてインデックス戦略のうち、どの部分がビジネスで強みを持っていく部分なのかを先に定義してDBを選択しなければならないという内容が最も記憶に残りました。 最近GenAI関連で様々なサービスが発売されていますが、その中で自分のビジネスでどのような内容を必要としているのかの把握が先行されなければならないと思います。
市場の変化と市場の要求事項を満足させ、これを加速させることができる答えはAWSにあるようです。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner