MEGAZONEブログ

ノーコードでデータレイクを高速スタート
No-code data lake fast start
Pulisher : Cloud Technology Center パク・ソジョン
Description : No-codeでデータレイクを構築するワークショップセッション
はじめに
最近Low-codeやNo-codeサービスが多く登場しています。AWSでもNo-codeベースでデータレイクを構築できるサービスがあり、そのサービスを見てみたいと思ってセッションに申し込みました。 このセッションはBuilder’s sessionで簡単な説明の後、実習が行われるセッションでした。
Data lake

データは重要な資産となり、これを基に顧客が何を望んでいるのか、今後何を望んでいるのかを予測し、顧客により良い経験を提供することが可能になりました。 また、データを基に既存のプロセスをさらに効率化することができます。この時、データ活用の核心要素であるデータレイクは、定型、非定型および半定型のデータをすべて積載する中央データストレージの役割を果たします。 ストレージとコンピューティングをデカップリングし、安価にデータを保存することができます。
データレイクを構築するための一般的なプロセス
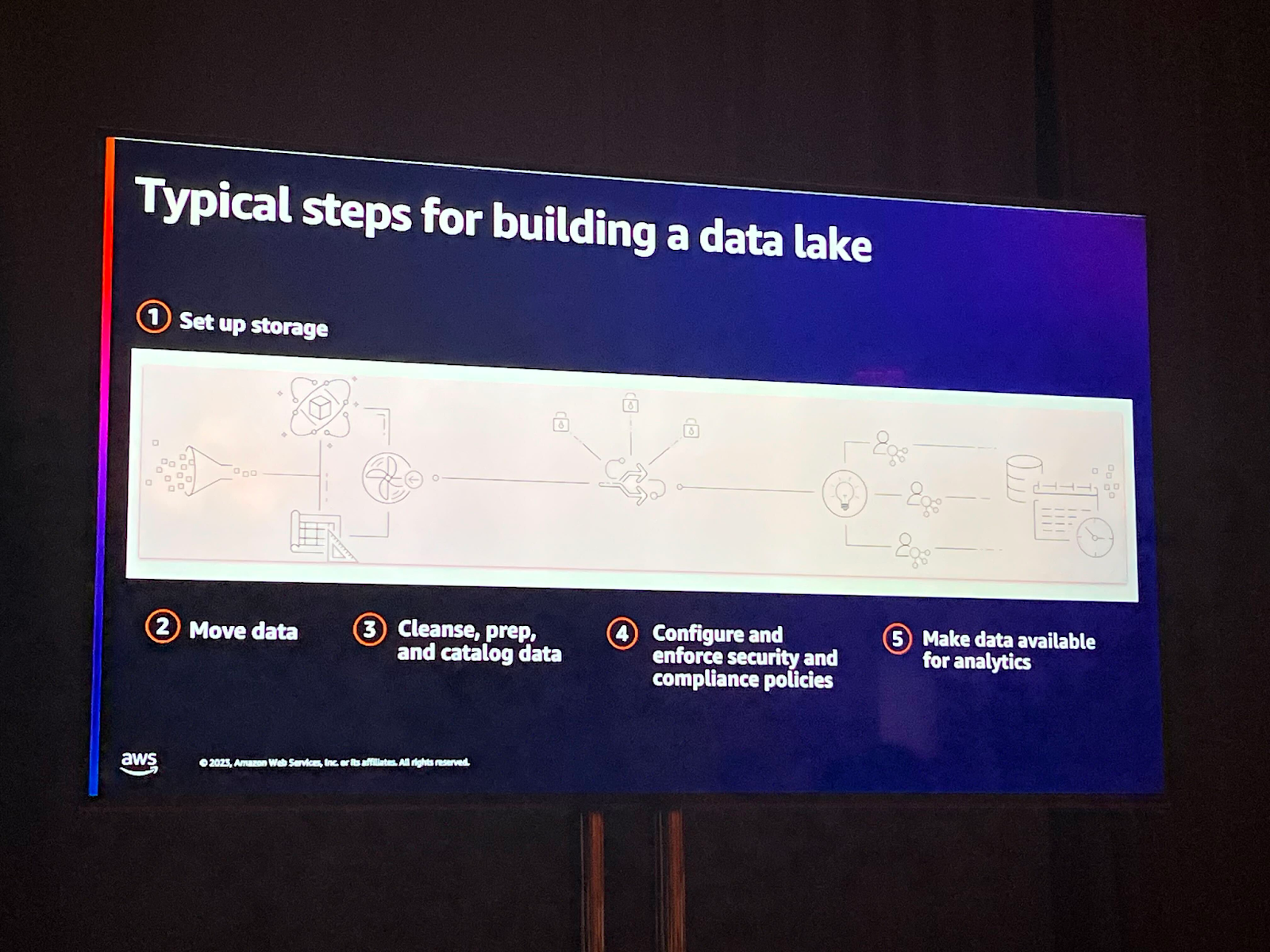
上のフローチャートはデータレイクを構築する一般的なプロセスです。データソースがあり、このデータを移した後、ETLプロセスを経由することになります。データを精製し、コンプライアンスポリシーに合わせてセキュリティ関連設定もすることになります。
アーキテクチャの概要
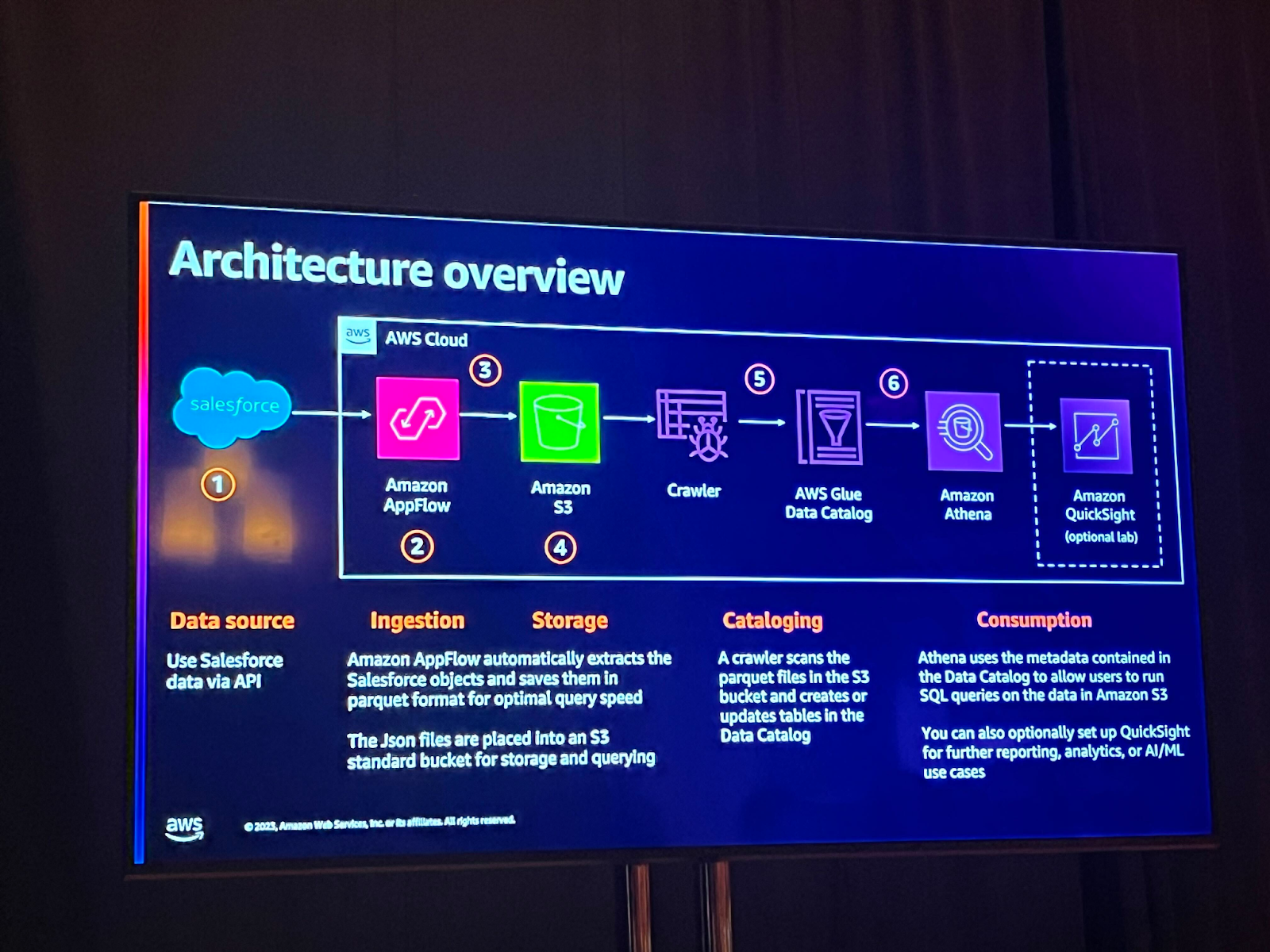
セッションで一緒に実習することになったセッションは以下の通りです。Amazon AppFlowは、3rd Party SaaSアプリケーションとAWSサービス間でデータを安全に転送することができるマネージドサービスです。 これにより、No-codeベースでデータレイクを構築することができるようになります。
Amazon Appflowで生成されたJSON/Parquetファイルは、保存とクエリのためにS3バケットにロードされます。GlueクローラーはこれらのファイルをS3バケットからスキャンし、AWS Glueデータカタログにテーブルを生成または更新します。Glueデータカタログに含まれたメタデータを基にAthenaを使ってAmazon S3のデータに対してクエリを実行することができます。
私が行ったワークショップの内容は下記の通りです。
ワークショップ内容
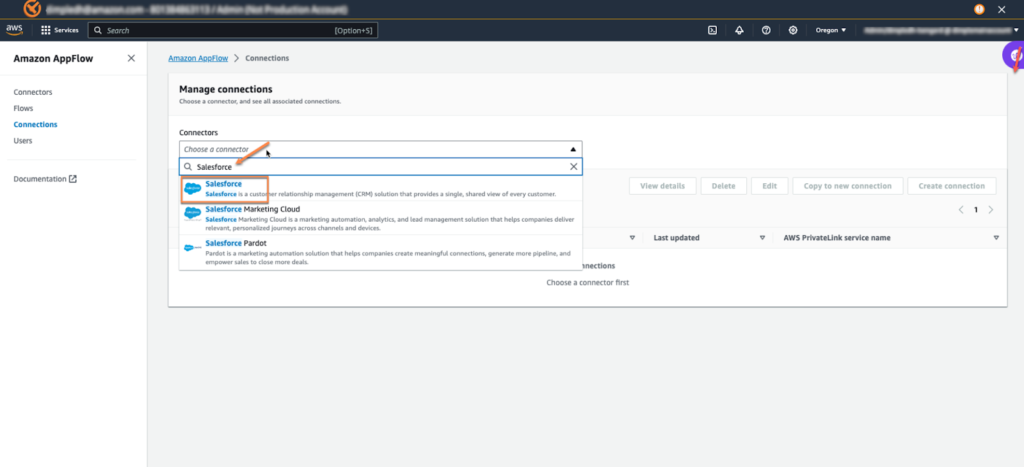
AppFlowページでConnectionsを作成するを選択し、SalesForceをconnectorとして選択します。
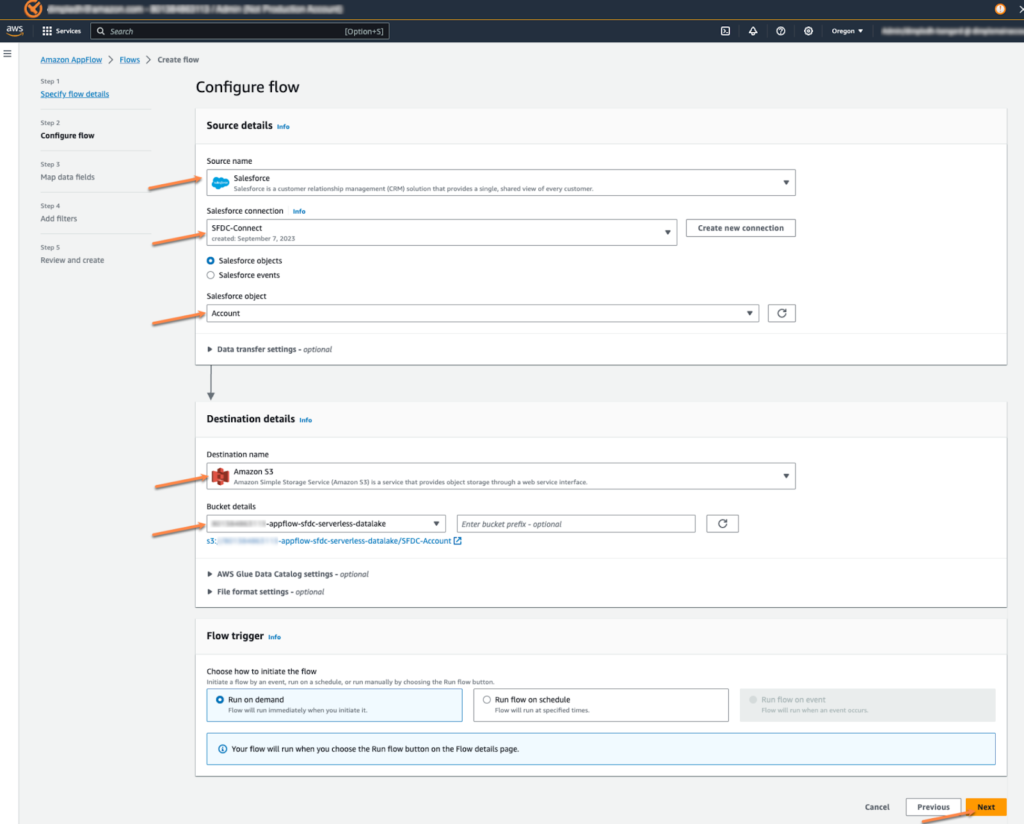
その後、Flowも作成するを選択してソースをSFDCに、connectionは先ほど作成したconnectionを選択します。移管するオブジェクトも一緒に設定します。 その後、データを移管する対象をS3に選択します。
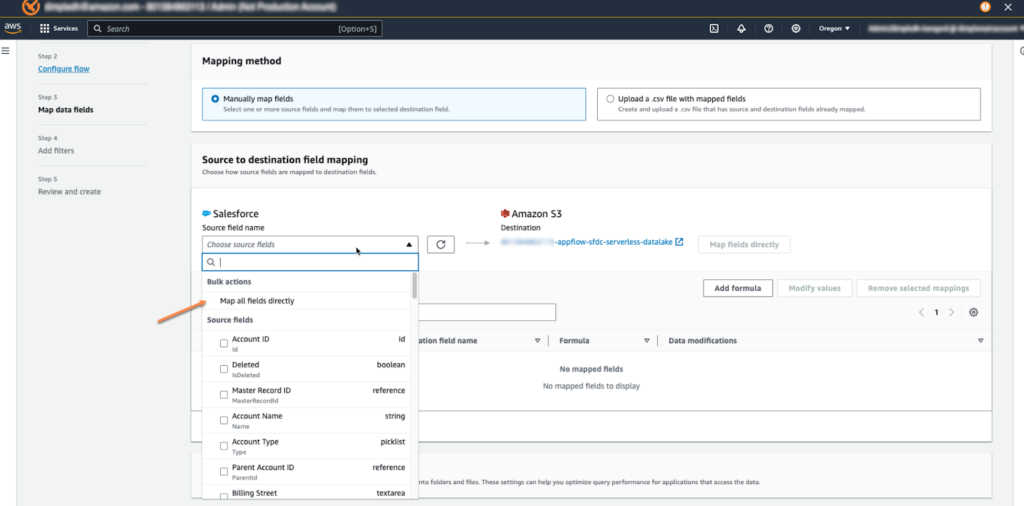
ソースとターゲット間のフィールドマッピングが必要ですが、この時、すべてのフィールドを直接マッピングするように選択します。 次のステップは特別な進行なしにflowの生成を終了します。生成が完了したら、Run flowで移管を実行させます。
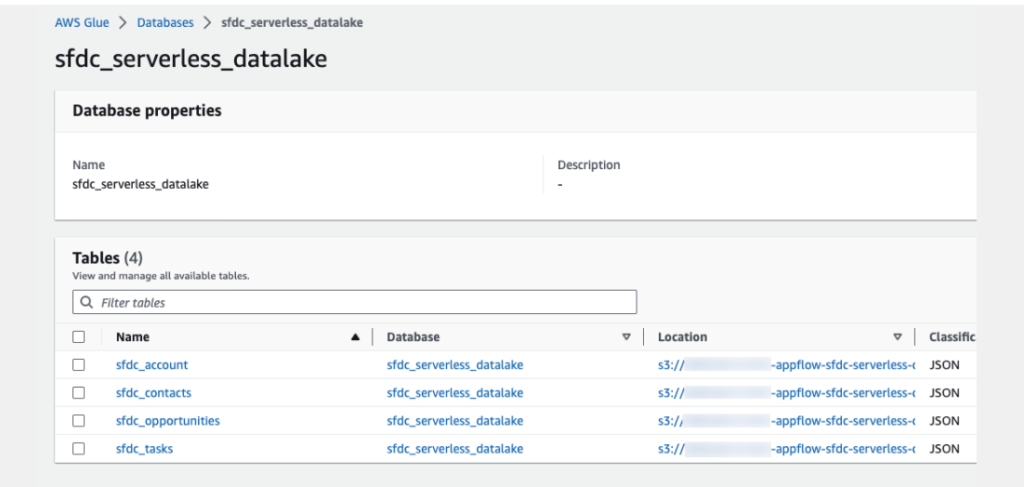
移行が完了した後、S3に接続してバケットを確認すると、Appflowを活用してデータが移行されたことが確認できます。
その後、一般的に進めるようにS3 Glue Crawlerを生成して実行したらAthenaでもデータクエリが可能です。
セッションを終えて
データレイクを構築するというと多くの段階があるようですが、AWSで提供されるNo-codeサービスを通じて簡単にデータレイクを構築することができました。 また、データレイクの概念のようにデータを分析してインサイトを得るためには様々なデータソースを一箇所に統合する必要がありますが、Appflowは様々な3rd Partyデータソースとも簡単に統合が可能です。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner