MEGAZONEブログ

Goldman Sachs:The journey to zero downtime
ゴールドマン・サックス:ダウンタイムゼロへの道
Pulisher : Mass Migration & DR Center キル・ジュンボム
Description : 金融圏のゼロダウンタイムについて、ゴールドマン・サックスの事例から紹介するセッション。
はじめに
金融圏のZero downtime、本当に可能なのか? 世界最高の投資銀行の事例が気になり、私たちが見逃していたのはどの領域なのかを把握したいと思います。
ゴールドマン・サックスは銀行のほぼすべてのコンポーネントをAWSで実装しており、数百のマイクロサービスとエンジニアが高可用性を維持するために多くの努力をしています。しかし、Zero downtimeは現実的に不可能に近い環境なので、near Zeroを話しているのか、本当にZeroを話しているのか疑問に思いながらセッションに参加しました。
セッションの概要紹介

高可用性を維持しようとした理由は、予期せぬイベントに備える弾力性、顧客との信頼、継続的で中断のないサービスの提供、そして決済SLAのためです。
ゴールドマン・サックスは、Transaction Banking(TxB)運営のためのアプリケーション・メトリックと利用率メトリックおよびSLAを測定しています。定期的な業務中断時間を除き、SLA上許容される障害時間は1ヶ月に3時間程度です。


このため、高可用性のアーキテクチャを検討し、構築してきました。
高可用性のためのアーキテクチャを構築する際に持っていた原則は5つで、特定のサービス、技術、思想を遵守し、サービスは独立して配布し、可能な限りアカウントとサービスを区別してプロジェクトを進めました。
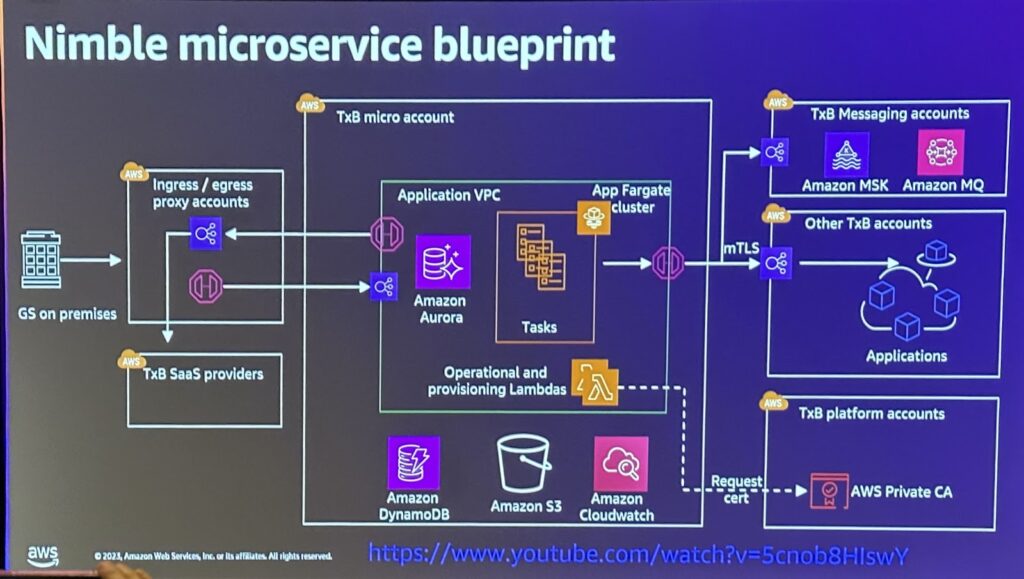
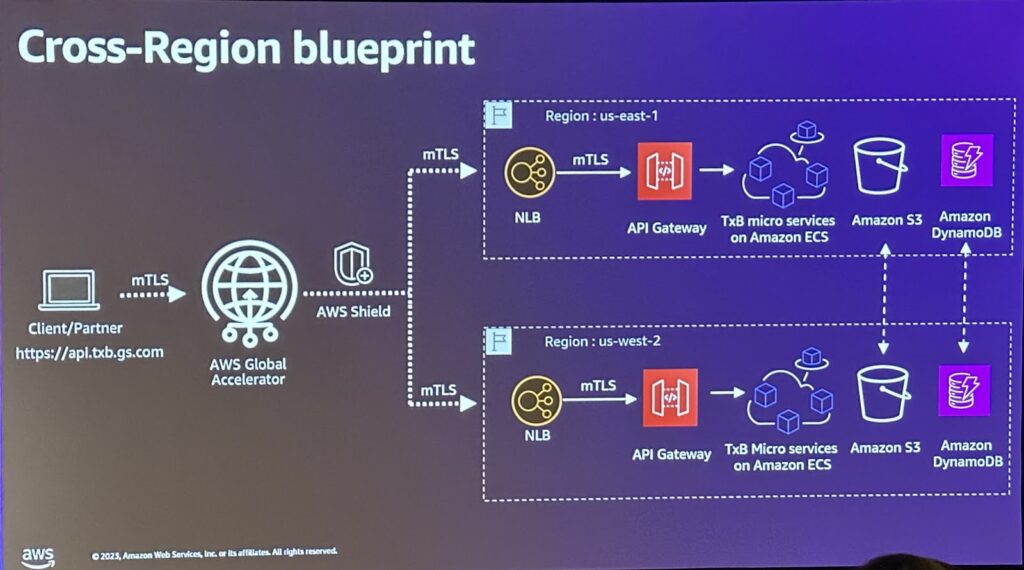
(ゴールドマン・サックス TxB 基本アーキテクチャ)


Zero Downtimeのためのデプロイメント戦略を考えながら、なぜ Zero Downtimeでなければならないかについて考えました。
印象的なことの一つは、開発者たちが週末に仕事をしたくないので、平日にダウンタイムなしでDeployできる方法を考えたということです。 通常、私たちはサービスの中断や影響を最小化するために夜間や早朝、週末の作業を要請して進行するのが一般的ですが。 確かに制御され、制限された状況でなければ、より大きな挑戦意識が生まれ、高い飛躍をすることができるようです。(私たちも週末に仕事をしたくないのに、週4日勤務すれば、大きな革新も早く来るのではないでしょうか?)
他にもCD、機能検証のためにこのような目標を持つようになったそうです。

Statelessサービスの展開戦略としては
・Blue-Green Deployment活用:ステージング環境で新しいアップデートを検証した後、プロダクションに切り替えてユーザーに新しい機能を迅速に提供する。
・Zero Downtime ロールバック:ロールバックが必要な場合、ブルー・グリーン戦略を通じ、以前のバージョンに迅速にロールバックを行い、ダウンタイムを最小限に抑えます。
・Health Check活用:statelessサービスでは、効果的なヘルスチェックを通じて、新しいバージョンのアプリケーションが正常に動作することを確認し、これにより問題発見及び対応を迅速に行う。
などを紹介しました。
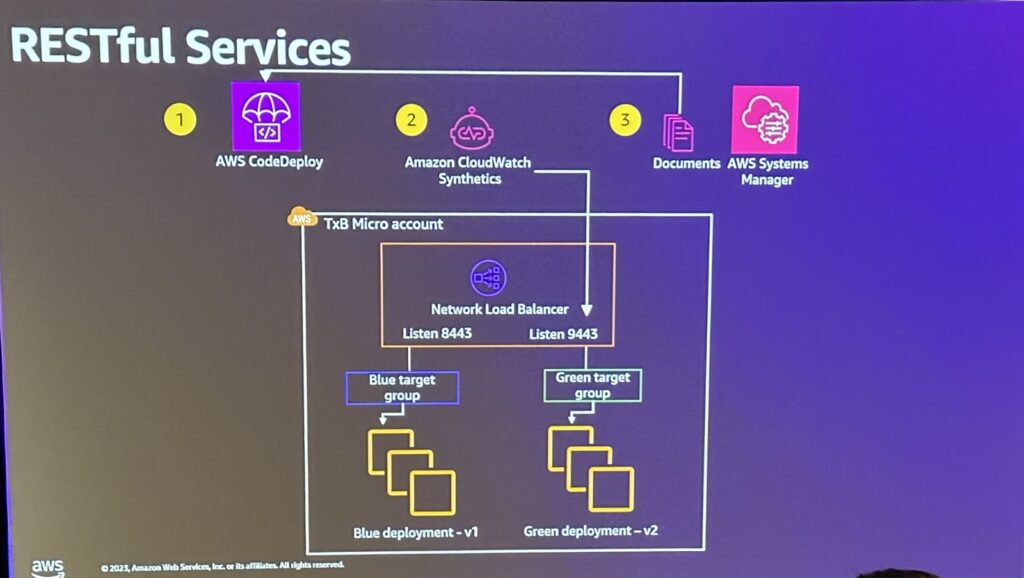
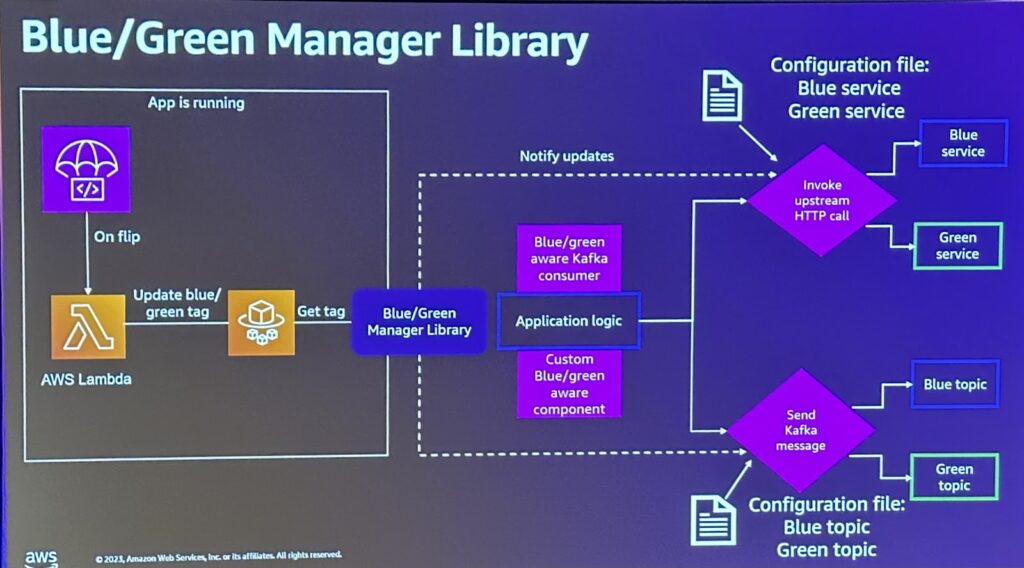


stateful resourcesの展開戦略としては
・Rolling Deploymentの注意:Statefulサービスの展開はデータの状態を維持する必要があるため、ローリング展開時には特別な注意が必要で、各ノードのアップデートが完了する前に次のノードのアップデートを行わないなど、安定性を考慮したローリング戦略が必要。
・Amazon Aurora活用:Amazon Aurora複製を使用して複製データベースを作成したり、書き込みAPIを無効にすることができます。
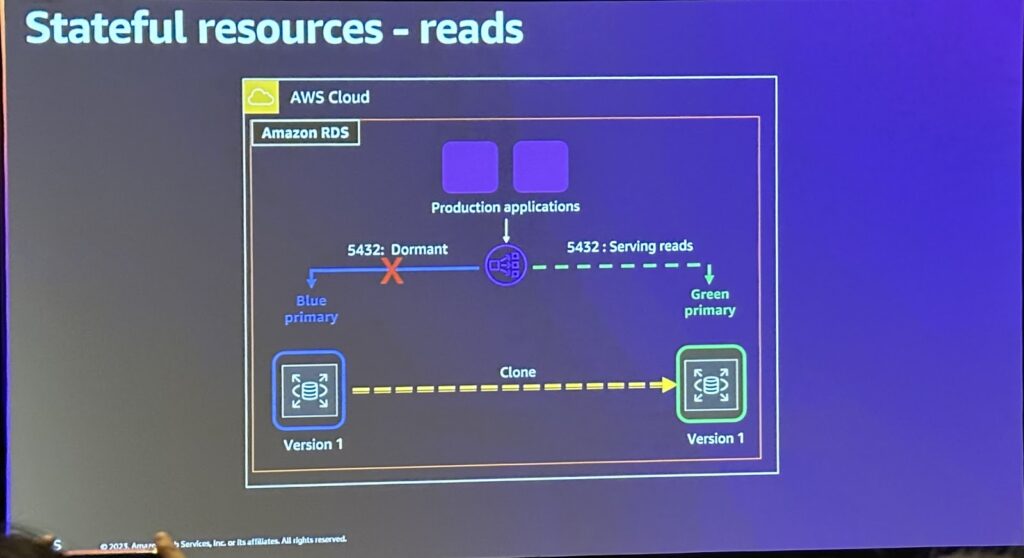
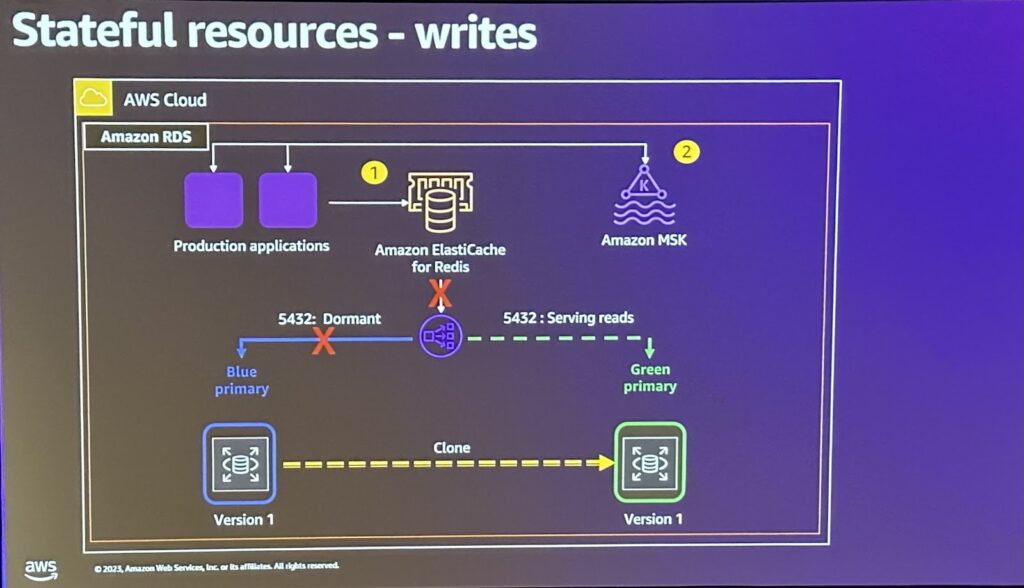
リリース手順は以下のプロセスを遵守しています。




Key wins項目としては
・48-Hour Release Validation Time: リリースに対して48時間の検証時間を導入することで、リリースの信頼性と安定性を向上。
・平日のリリースとステージングの活用:週末のリリースを避け、平日にリリースを計画し、木曜日や金曜日にステージングを行い、安定的なデプロイを実現。
・Release Incidentsの最小化: 厳格な検証とトランザクションレビューを通じてリリースインシデントを最小化し、安定性を確保。
上記のような主な成功要因と様々な戦略と技術を総合的に活用することで、安定的で効果的なリリース管理を行うことができました。

Lessons Learned
Lessons Learnedには
・Health CheckとCanariesの活用:複雑なヘルスチェックでアプリケーションの正常稼働を迅速に判断し、ネットワークロードバランサーとアプリケーションロードバランサーの違いを理解し、効果的なリリースを実現。
・ネットワークロードバランサーとアプリケーションロードバランサーの違い:ネットワークロードバランサーは接続に基づいてトラフィックをルーティングするため、サーバーのシャットダウンと接続維持に注意する必要があります。
・サーバーのシャットダウンと接続管理: サーバーのシャットダウン時間と接続維持に対する綿密な計画でクライアントとの接続切断を防止
他にも、Release Validation Timeの重要性、Zero Downtime Rollbacksの効果、Blue-Green Deploymentとスケールテストなど多くの教訓を学んだとのことです。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner