MEGAZONEブログ

Future-proofing your applications with AWS databases
AWSデータベースでアプリケーションの将来性を高める
Pulisher : Cloud Technology Center ペク・ソジョン
Description : AWSのDB関連サービスのアップデートとビジョンについて紹介するセッション
はじめに
re:Invent 期間中、DBサービスに関する多くのアップデートがありました。 このようなサービスアップデートを全体的に整理し、AWSのDBに関するビジョンを知ることができるセッションになると思い、このセッションに参加しました。
セッションの概要紹介

AWSはこれまで継続的にAWS DBサービスに多くの革新を成し遂げました。
AWSは、データを扱う人々が他の付加的な作業に気を取られることなく、コア作業に集中できるように支援したいと考えています。 また、データシステムの拡張性、ML関連機能などをさらに改善し、今も継続してDBサービスを発展させています。

昨年、Zero-ETLのビジョンを発表しました。
Zero-ETLにより、お客様がETLプロセスに気を取られることなく、アプリケーション開発に集中できるようにしたいと考えています。 この機能は、DWとDB間のデータ移動をより簡単にし、ETLプロセスを簡素化します。Auroraの多くのトランザクションデータをRedshiftで迅速に使用し、ML機能も使用してインサイトを得て、これを基に顧客体験を向上させ、ビジネスを発展させることができます。
今回、新しいZero-ETL関連のpreviewがさらにリリースされました。従来はRedshiftとAurora MySQL間のintegrationが可能でしたが、今はAurora postgre、RDS mysqlおよびDynamo DBが追加されました。 そしてOpenSearchとDynamo DB間のZero-ETL intergrationがGAになりました。
このようにサービス間のIntergrationをさらに強化しています。
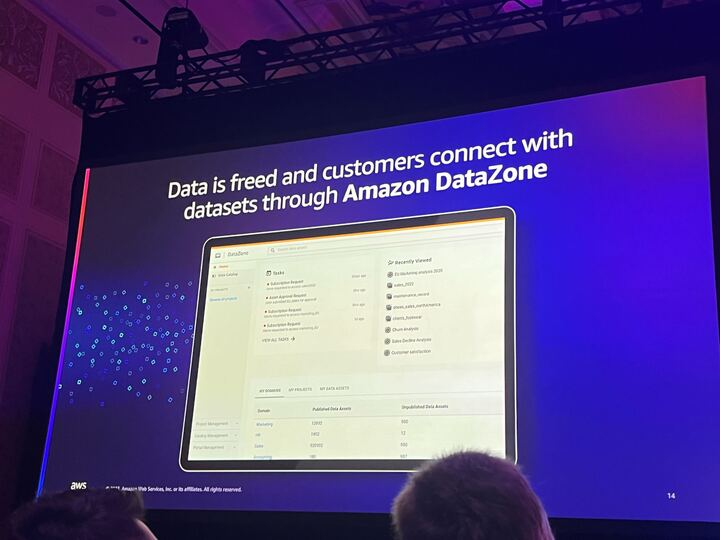
堅固なデータガバナンスがあれば、ユーザーが必要なデータを探し、反復的な作業を減らすことができるため、データをより迅速に移動させることができます。Data Zoneを使えば、ガードラインを作り、ビジネス価値を生み出すために適切なデータを配置することができます。

訓練されたモデルとデータに基づいて、性能とコストを最適化することができます。この目的は、前述したようにユーザーがこのような部分を気にしなくて済むようにするためです。
・Amazon QuickSight ML-powered forecasting: 過去の指標パターンを基に将来の指標を予測
・Amazon CodeWhisperer Integration with AWS Glue Studio: CodeWhispererベースのコーディングアシスタントで、ETL jobコードを生成する。
・Amazon Q generative SQL in Amazon Redshift Query Editor: Redshiftクエリ編集ウィンドウで自然言語でクエリに関する質問をすると、ユーザーの意図やクエリパターンなどを把握してクエリの提案を提供します。

関係型DBに対して迅速かつより深く投資をしており、今年にも下記のような関係型DB関連のアップデートがありました。
・Aurora I/O Optimized:読み取りと書き込みI/O作業に対する料金が発生せず、価格対比高い性能と料金予測を容易にする新しいAurora構成タイプで、I/O集約的なリソースに使用するのに適しています。
・RDS Custom for SQL Server BYOM: SQL Serverでインスタンスを作成する際、独自のSQL Serverインストールメディアを使用することができます。
・Aurora Optimized Reads:Aurora PostgreSQLで利用可能な機能で、データセットがDBメモリサイズを超える場合に適しており、クエリ遅延時間を最大8倍向上させることができます。
・Vector database on Aurora and RDS for PostgreSQL: Aurora PostgreSQLおよびRDS PostgreSQLでpgvector拡張をサポートし、MLモデルの埋め込みをDBに保存し、効率的な類似性検索を行うことができます。

1.DocumentDB I/O-Optimized: 読み取りおよび書き込みI/O操作に対する料金が発生しないため、価格対性能比が高く、料金予測が容易な新しいAurora構成タイプで、I/O集約的なリソースに使用するのに適しています。
2.ElastiCache for Redis 7.1:パフォーマンスが大幅に改善され、クラスタごとに毎秒5億件のリクエストを処理できるようになりました。
3.DocumentDB integration with SageMaker: SageMakerでDocumentDBにあるデータを分析可能。

今年のアップデートではRDSエンジンが追加されましたが、IBMのDb2エンジンが追加されました。AWS上で素早く簡単にDb2エンジンを生成することができ、他のRDSと同じようにMulti-AZ、BYOLモデルなどがサポートされます。

特定の目的のためのDBエンジンにもアップデートがありました。既存のGraph DB NeptuneはNeptune DBに名前が変更され、Neptune Analytics GAを発表しました。 これは完全に管理されたグラフ分析環境を提供し、グラフサイズに応じて自動的にコンピューティングリソースを割り当て、すべてのデータをメモリに迅速にロードして数秒以内にクエリを実行することができます。 また、Neptune AnalyticsでNeptune DBやS3データを迅速にロードして分析が可能です。 グラフデータとベクターを一緒に保存することで、ベクターサーチをより速くすることもできます。

このように既存のサービスでエンジンが追加されたり、既存のサービスの機能をさらに発展させたりしました。
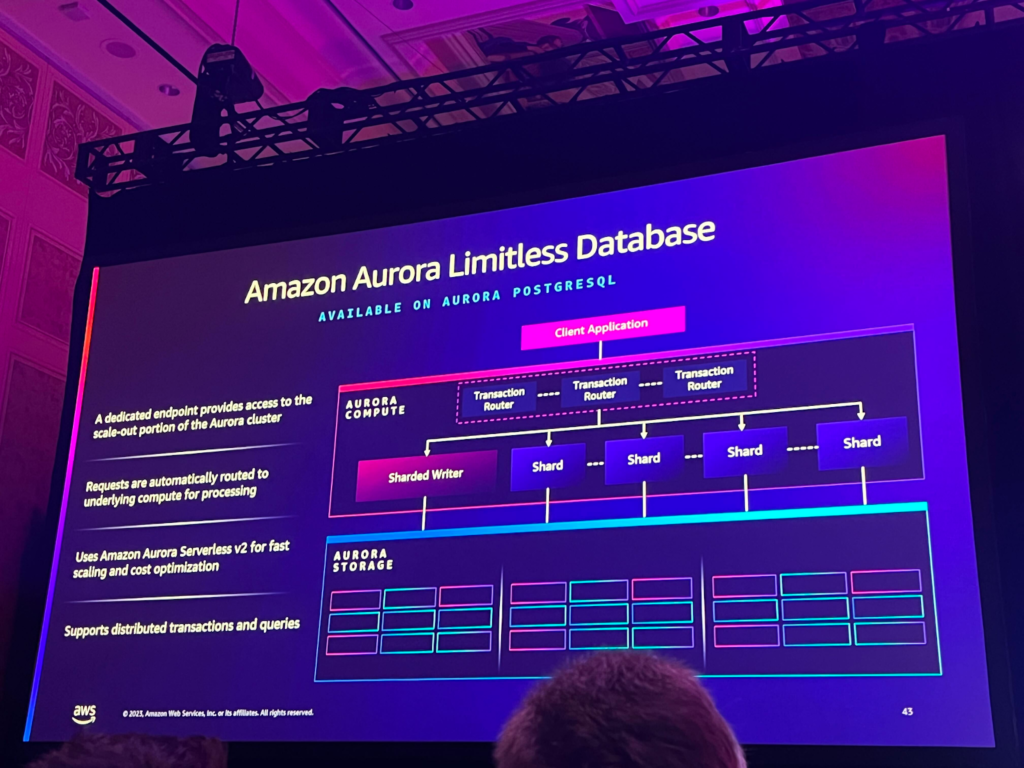
Aurora Limitless DBのpreviewが発表されました。Aurora PostgreSQLで利用可能で、この機能を使用すると、書き込みスループットとストレージを制限なく拡張することができます。サーバーレスエンドポイントを通じてデータとクエリを1つのDB内の複数のサーバーレスインスタンスに分散し、各シャードは独立して拡張されます。

ElastiCache Servelerssが正式リリースされ、ElastiCacheをサーバーレスオプションとして提供し、インフラ管理なしで1分以内にキャッシュを作成し、使用量に合わせて容量拡張が可能です。既存のElastiCacheと同様に、RedisとMemcachedの二つのオープンソースと互換性があります。

他のタイプの分析も非常に重要ですが、ベクトルやGeospatialデータのようなvariable fieldは、Document DBのようなキー・バリュー・ストアに検索しやすいフォーマットで保存するのがより良いです。
今回のリインベントで新しく導入された機能の一つであるDynamoDBとOpenSearch間のZero-ETL機能を通じてOpenSearchでのデータ変更の流れを自動的にDynamoDBでキャプチャすることができます。これにより、DynamoDBでOpenSearchのfull-text search、ベクターサーチの検索機能を使用することができます。

最近の話題であるGenAI関連のアップデートも見逃せません。 GenAIアプリケーションを開発するためには、基礎モデル、データストア、Vector DB、およびエージェントが必要です。

このため、AWS DBサービスにもvector capabilityが追加されました。まだ、一部はpreviewで提供されていますが、下記のDBサービスとDyanmoDBも先に説明したZero-ETLベースでこの機能が使えるようになりました。
・OpenSearch
・Aurora PostgreSQL
・RDS PostgreSQL
・MemoryDB
・Neptune Analytics
・Document DB
セッションを終えて
このように2023リインベントで発表されたDB関連のアップデートについて見てみました。 キーノートでもAIとデータの内容が中心でしたが、DB関連のアップデートだけをまとめたセッションを聞いてみると、改めて多くのアップデートがあったことを感じました。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner