MEGAZONEブログ

Get the most out of your data warehousing workloads
データウェアハウスのワークロードを最大限に活用する
Pulisher : AI & Data Analytics Center チェ・スンヒョン
Description : Redshiftを費用対効果の高い方法で使用する方法を紹介するChalkTalk
はじめに
AWSのRedshiftをDatawarehouseに選択することが多いですが、Redshiftインスタンスのタイプによってコストが大きく発生することもあります。Redshiftを目的に合わせて選択して最大限活用できる方法について整理が必要だと思い、このセッションを登録しました。
セッションの概要紹介
セッションはChalk talkで行われ、開始時にRedshiftを使用している、またはこれから使用したい人が参加者の大半を占めていました。Redshiftを費用対効果の高い方法で使用する方法について行われました。
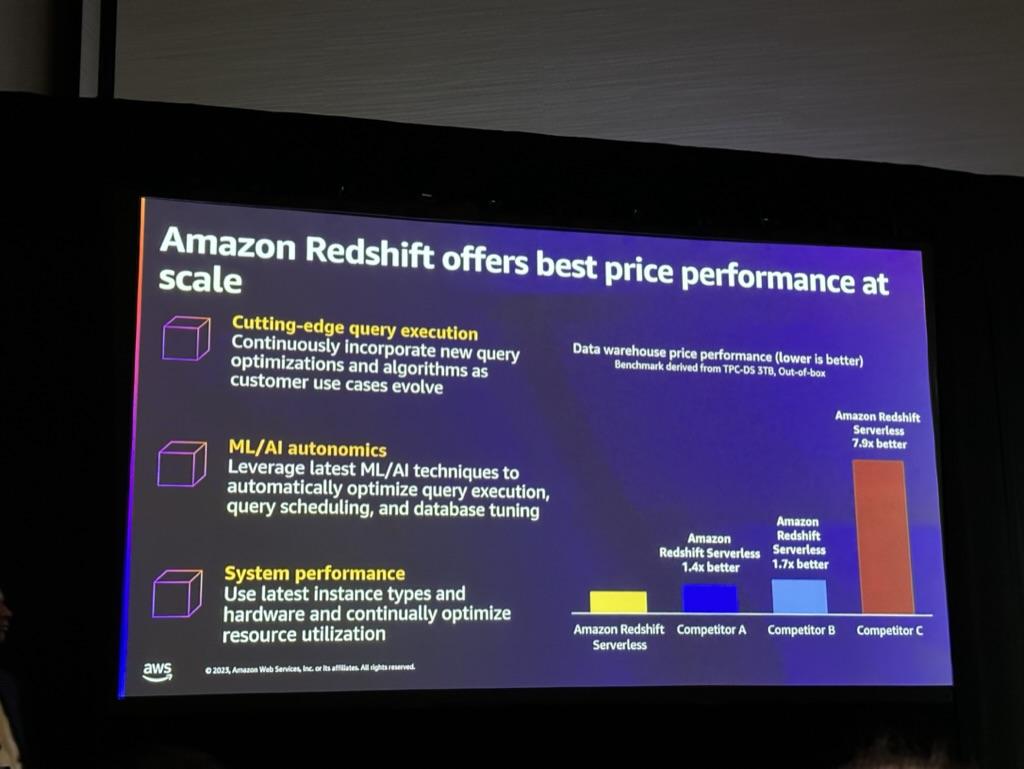
規模に合った最高の価格対性能を提供するため、最近Redshiftでは様々な機能を提供しています。
1.Cutting-edge query execution
新しいクエリ実行アルゴリズムなどが含まれます。
2.ML/AI autonomics
・ML/AIを活用して実行されているクエリを最適化し、データベースのチューニング、クエリのスケジューリングの機能が追加されました。
・高速暗号化、同時性最適化、ワークロード管理機能が含まれます。
3.System performance
・インスタンスとハードウェアを効果的に使用するために、リソースの最適化作業が行われます。
・Auto Scaling、Data Sharing、Serverlessなどの機能が含まれることがあります。
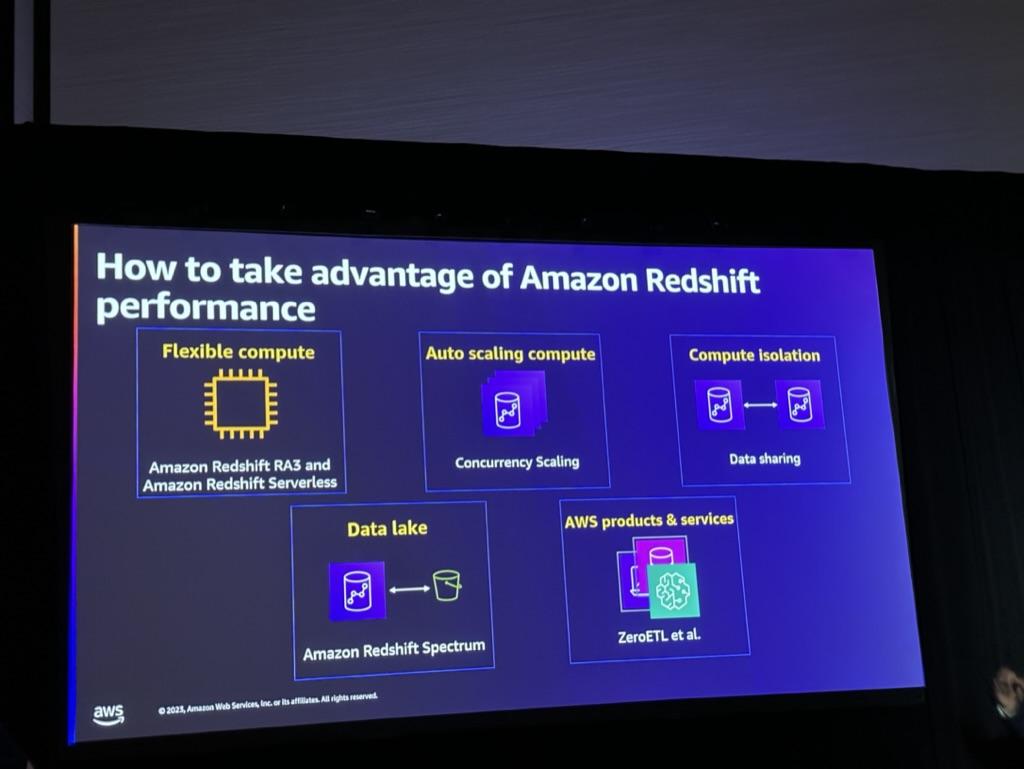
Redshiftを使用する場合、パフォーマンスを向上させることができる5つの機能があります。
1.Flexible compute
- 初期にRedshiftを構築する場合、必要なサイズに対する見極めが難しいため、Serverlessを活用してより柔軟にRedshiftを利用することができます。
- この機能の説明の際、下記のような質問と回答がありました。
Q. 既存のRedshift Provisionedを使用していたのですが、Serverlessに簡単に移行できますか?
A. Redshift Snapshotを活用し、Provisioned <-> Serverless間のデータ移行が可能です。
2.Auto Scaling compute
- 同時性拡張機能を活用してAuto Scaling Computeを利用することができます。
- 同時性拡張により、クエリがキューで待機するのを防ぐため、追加クラスタ容量を自動的に追加します。この時、既存のクラスターを含めて最大10個まで構成が可能です。
3.Compute isolation
- Data Sharingを活用してコンピューティングとストレージを分離して利用することができます。
- Producerに保存されているデータをSharingを通じてConsumerクラスタコンピューティングで分析することができます。
4.Data Lake
- すべてのデータをRedshiftに保存するのではなく、S3 Data Lakeを通じてRedshift Spectrumに接続することで、Redshiftのストレージコストを削減することができます。
5.AWS Products & Services
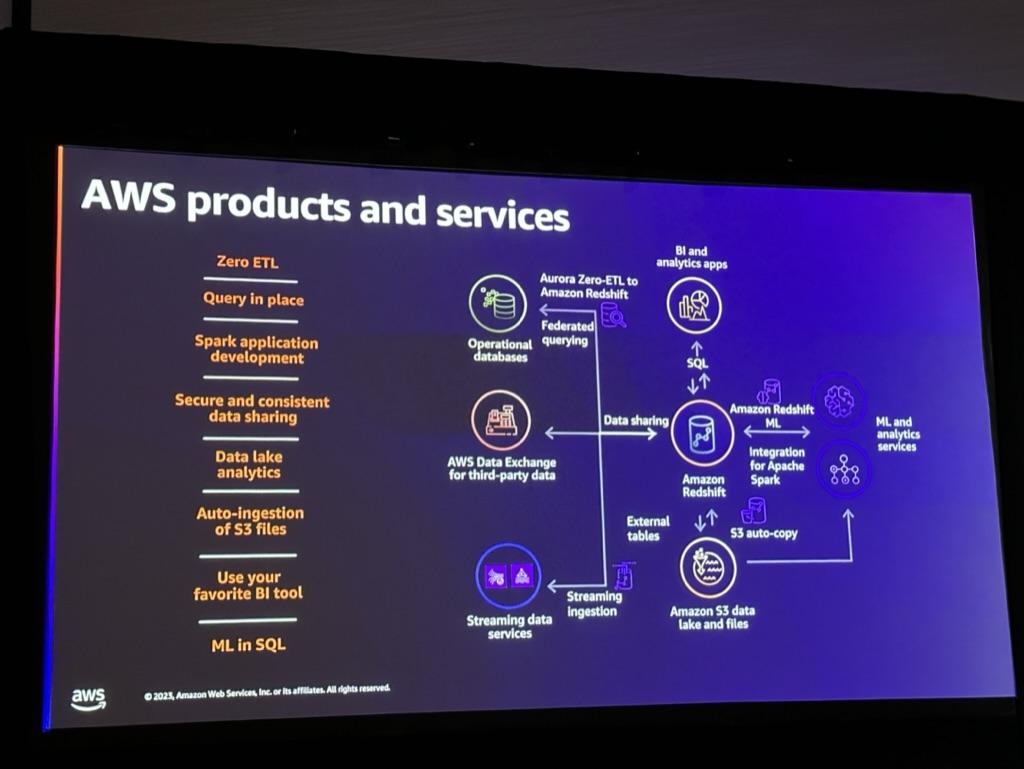
- KeyNotesで紹介されたようにAurora(Postgresql)、RDS(MySQL)、DynamoDBをRedshiftと接続して分析及び活用することができます。
セッションを終えて
RedshiftはAWS環境でデータ移行を進める時、基本的に一緒に構成されるサービスだと思いました。 初期構築段階で大きなインスタンスタイプを選択し、再度再構築する場合もありましたし、同時性機能を有効にしないため、クエリが長い間キュー内に蓄積される場合も多かったです。 もう少し効果的にRedshiftを使うことができる方法と機能について改めて整理することができました。
Get the most out of your data warehousing workloads
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner