MEGAZONEブログ

Build large-scale transactional data lakes with Apache Iceberg on AWS
AWS上のApache Icebergで大規模トランザクションデータレイクを構築する
Pulisher : Cloud Technology Center キム・ビョンジュ
Description:AWSでApache Icebergを使用してデータレイクを構築する紹介セッション
はじめに
最近、Data Lake分野でOpen Table formatあるいはLake Houseは非常に関心が高いテーマです。基本的に既存のS3のようなObject storage自体のImmutable(不変)属性のため、既存のData Lakeアーキテクチャでは不可能だったUpdate、Delete、Insertが可能になったからです。 しかし、このような魔法のような(?)技術には当然学ぶべき点があります。 そのため、Icebergをより効率的に使うためにこのセッションを申し込みました。
セッションの概要紹介

このセッションはIcebergについて簡単に紹介し、transactional data lakeをAWS上でHands onで実装する方法について説明するセッションでした。セッション当時、cloudwatchで設定されたアカウントのリージョンが間違っていて、直接実行することはできませんでしたが、AWS SAの方が実行画面と説明を一緒に共有してくれました。 そのため、このセッションレポートはノートブックコードを説明するレポートで構成しました。

icebergをglueで使うオプションやglueオプションです。
・session_id_prefix : このノートブックファイルはGlue Interactive Sessionを使って動作します簡単に説明すると、ローカル環境でIAM RoleベースでもAWS CloudのSpark環境を利用して開発することができるという点がメリットです。
・glue_version : Glueのバージョンに関する部分です。1.0~4.0までありますが、一般的に3.0,4.0が一番多く使われます。当然、高いバージョンが機能上サポートする機能が多く、性能もいいです。
・idle_timeout : interactive sessionのtimeout値を設定する部分です。60分間使わないとsessionが中断されて費用が請求されません。
・configure :該当Glue Sessionを開始する時に入力する設定値です。様々な設定が入ることができます。
※datalake-format : open table formatを決める部分で代表的にはiceberg, hudi, delta lakeなどがあります。

spark sessionの設定値は下記のようになります。
ここで使うcatalog_nameは実際spark sqlを使う時使うことになります。Glue Catalogを使ってIcebergテーブルを使う場合、このcatalog nameを使って使うことができます。
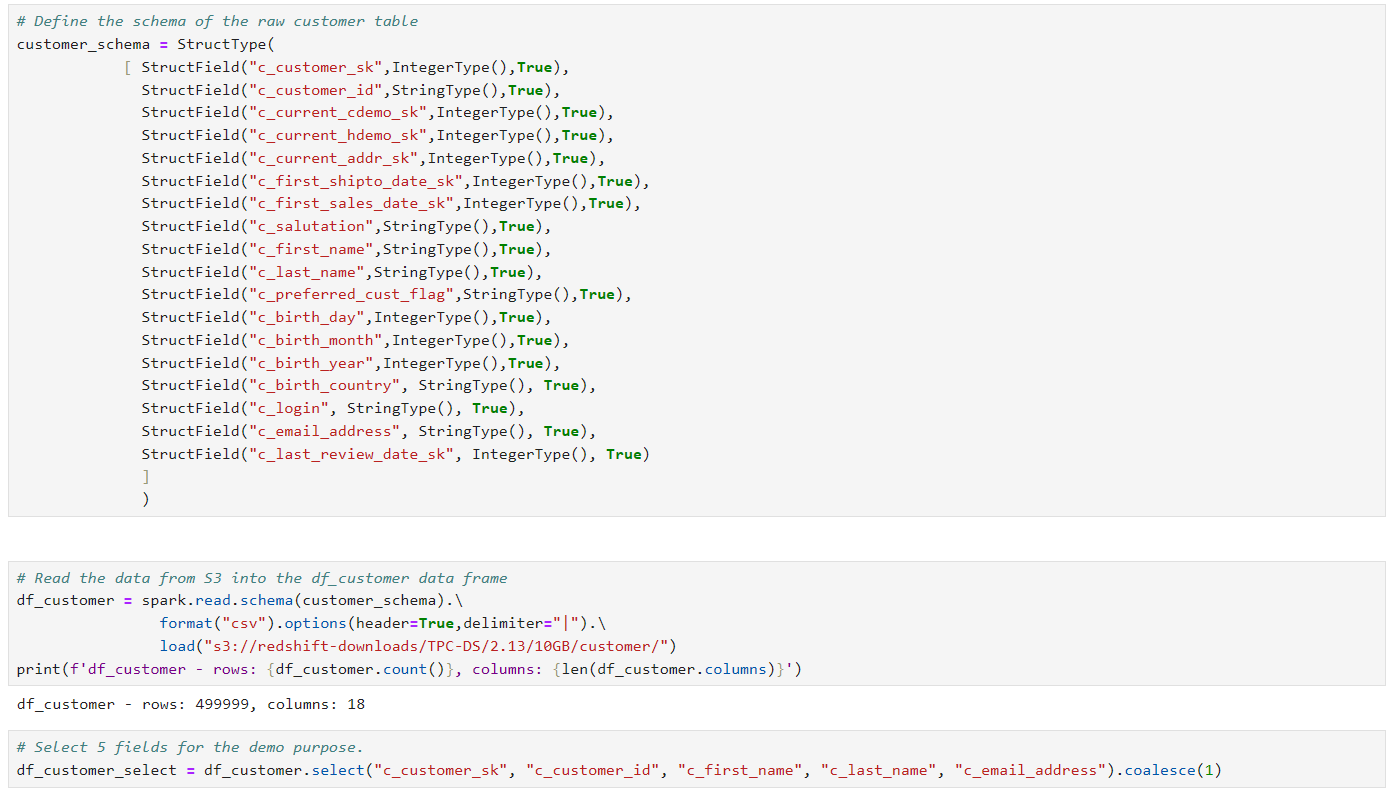
デモデータセットはredshift TPC-DSを測定するときに使うデータセットの一つである10GB customerデータセットを使います。このデータセットに関する情報と他のサイズのデータセットを使いたい場合は(amazon-redshift-utils/src/CloudDataWarehouseBenchmark at master – awslabs/amazon-redshift-utils – GitHub)を参照してください。
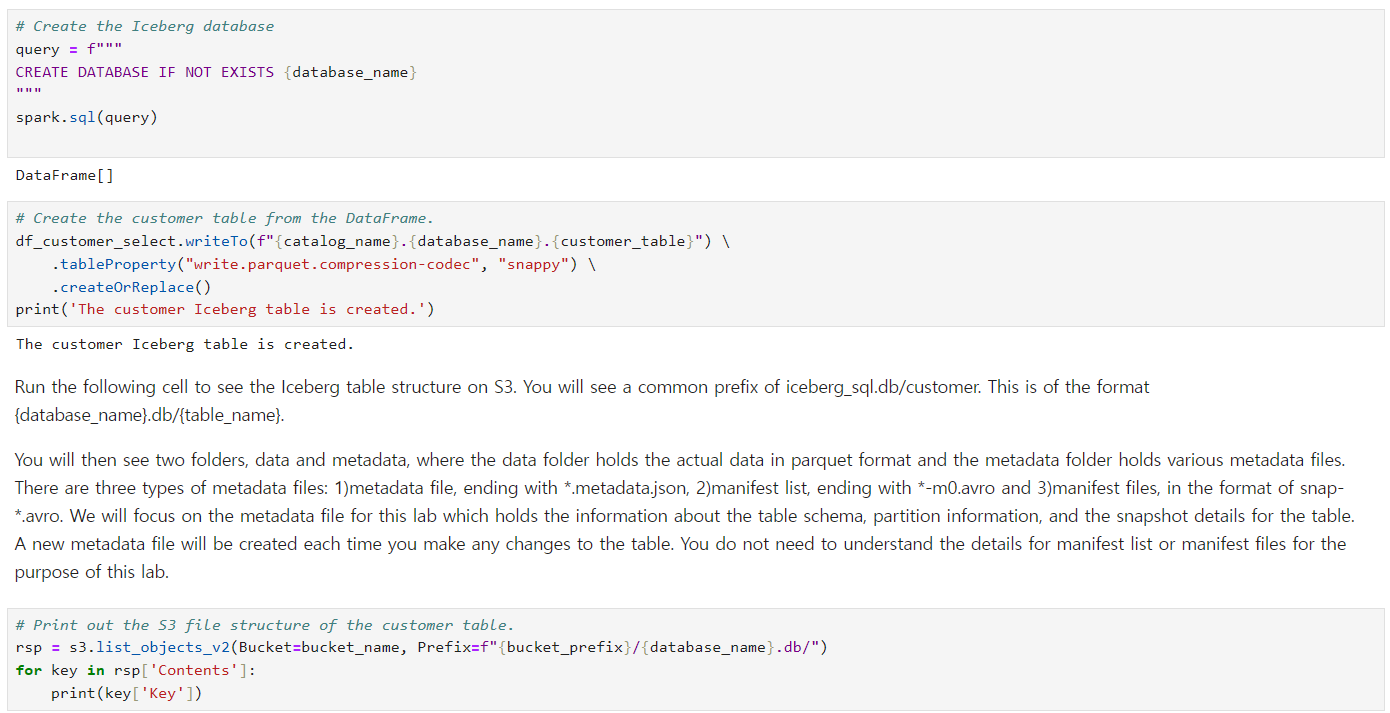
このコードではGlueデータベースを作成してSpark Dataframeを利用してicebergテーブルを作ります。 そして、S3バケットのデータ構造を確認します。
iceberg/iceberg.db/customer/data/00000-17-6a65377c-2e77-43c3-b2db-55d4ea710a00-00001.parquet -> 実際のデータファイルです。
iceberg/iceberg.db/customer/metadata/00000-87997b51-6f49-474f-907e-f74ea071fa70.metadata.json
iceberg/iceberg.db/customer/metadata/deac1eda-b66a-4fb5-9f3d-896c2e4b0c26-m0.avro
iceberg/iceberg.db/customer/metadata/snap-8619787751396069410-1-deac1eda-b66a-4fb5-9f3d-896c2e4b0c26.avro
data/フォルダの下にあるデータは実際私たちが入力したredshiftのサンプルデータが入っています。しかし、metadataフォルダは何でしょうか?このフォルダはデータファイルに関する情報と位置のバージョンを記録したファイルです。
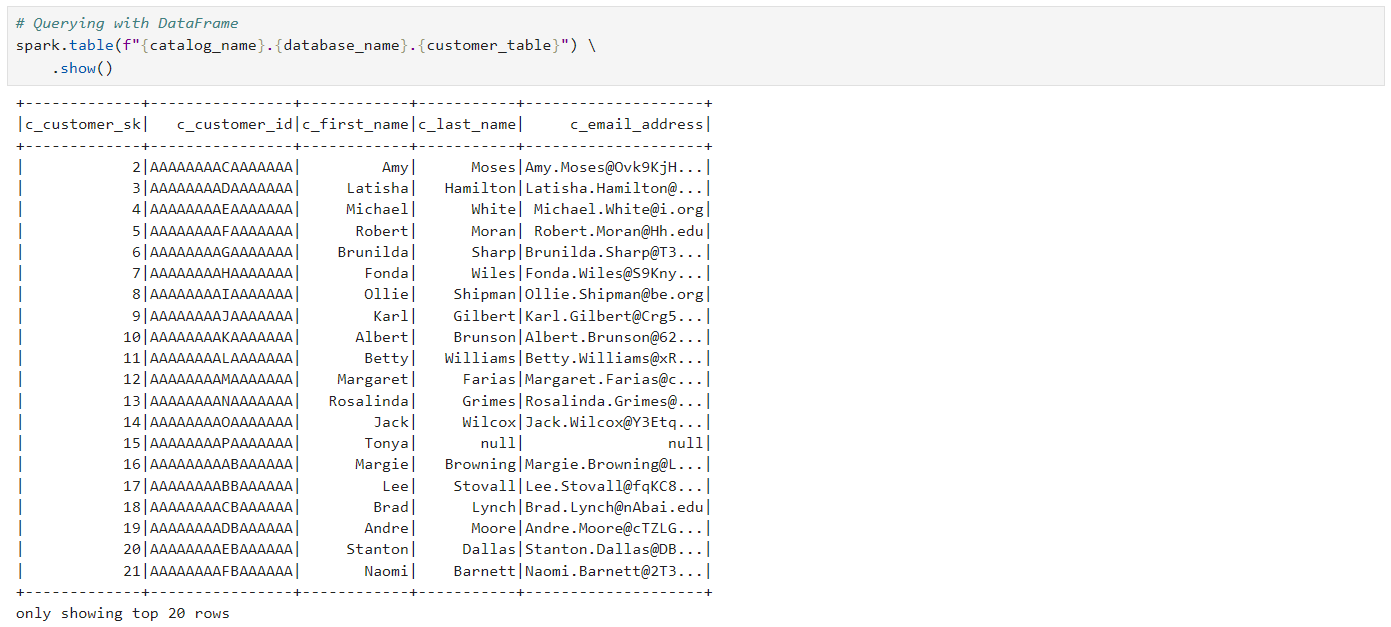
Icebergテーブルからデータを確認してみます。 既存と同じようにspark table,sqlを使って確認することができますし、必ずdatabase_nameの前に前回のspark session configで指定したcatalog nameを指定する必要があります。
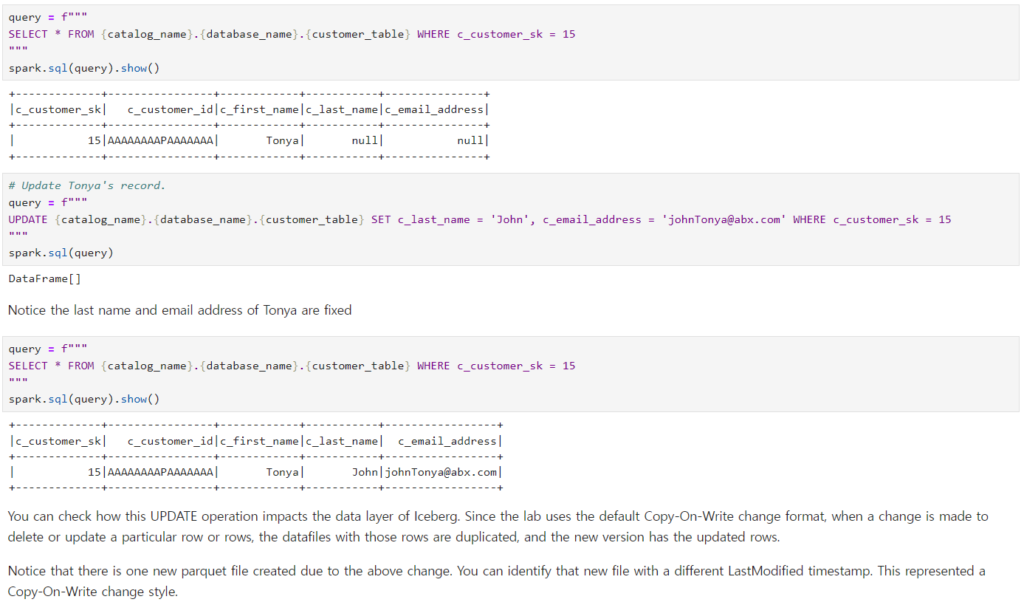
それでは、Icebergテーブルがサポートするupdateクエリを実行してみます。対象データは’c_customer_sk = 15’であるデータです。このデータをよく見ると、詳細情報が少し空いていることが確認できます。 UPDATEクエリで該当情報を埋めて確認してみます。 正常に入ったことが確認できます。

では、icebergテーブル(s3)には何が起きたのでしょうか? よく見ると、parquetファイルが二つに増えたことが分かります。UPDATEだからファイルが変わるんじゃないの? と思うかもしれません。しかし、覚えておいてください。S3はObject Storageで不変性を実行するため、ファイルを変更することができません。 したがって、このような方式をCOW(Copy on Write)といい、データを書く時、既存のファイルをコピーして新しく作成することを意味します。
では、このような同一データに対するVersioningはどこで行うのでしょうか?先ほど説明したmetadata/フォルダでその情報を管理することになります。
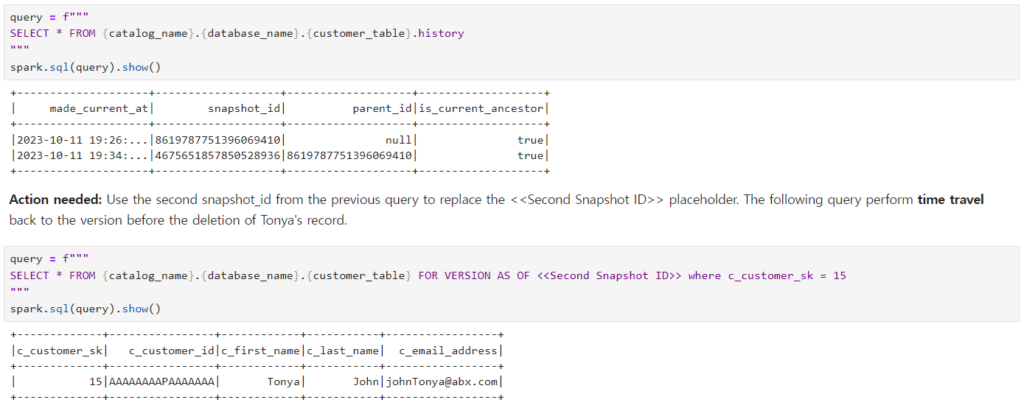
このようなデータ変更に関する情報を保管しているので、もう一つの強力な機能であるTime Travelもサポートします。この機能を一度確認してみましょう。 まず、Icebergのhistory情報を確認してみると、次のように初めてWriteされた瞬間1回目/2回目Updateされた瞬間2つのtransaction logのようなsnapshot idが撮られたことが確認できます。
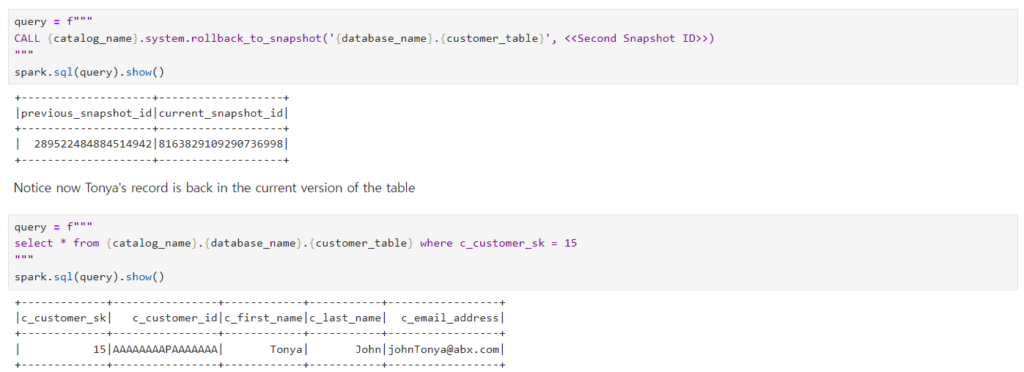
CALLクエリを使うか、関数を使うと、データをそのスナップショットの時点に戻すことができます。上の写真はスナップショットの時点を回してクエリを実行するシーンです。
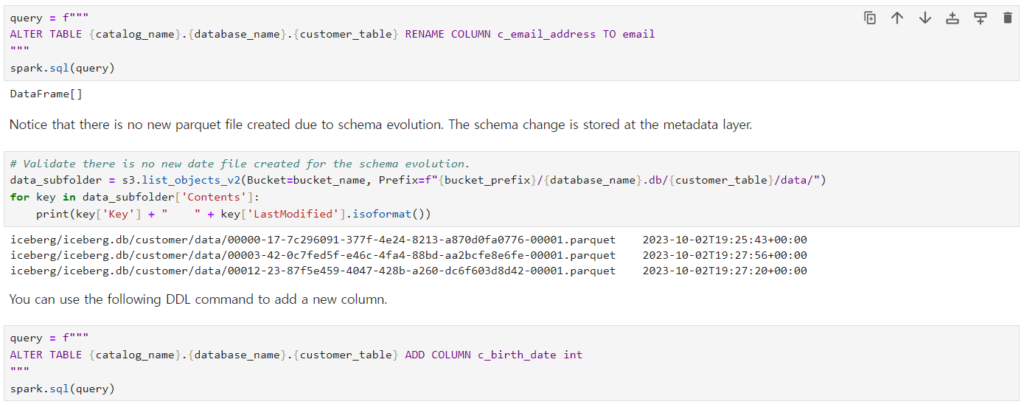
次に強力な機能はschemaの変更が自由という部分です。 すでにデータレイクを使ってるお客様なら、parquetファイルのカラムを変更するのは(…)考えただけでも恐ろしいことではないでしょうか。 しかし、上の画像を見ると… カラム名を変えたからといってファイルを全部再処理しますか?いいえ、既存の数と同じ数のファイルが残っていることを確認することができます。
セッションを終えて
直接Hands-onができなかったのは残念でしたが、基本的なIcebergの使用方法や構造について学ぶことができた機会だったようです。データレイクを使用中で、既存のデータレイクで制御が難しく、管理が難しかったら、一度は考えてみてもいいと思います。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner