MEGAZONEブログ

Scaling analytics with data lakes and data warehouses
データレイクとデータウェアハウスによるアナリティクスの拡張
Pulisher : Cloud Technology Center ペク・ソジョン
Description:AWSが提供するData lake及びData warehouseを活用したデータ処理方法についての紹介セッション
セッションの概要紹介
Why Zero-ETL?

ビジネスはデータから洞察を得、それを基に顧客体験を向上させます。有意義なデータを見るためには、様々なソースのデータを集め、一つの分析プラットフォームで分析する必要があります。 問題は、これを実装するのが思ったより簡単ではないということです。 ETLパイプラインを構築するのは数週間あるいは数ヶ月かかることもあり、このようなパイプラインを維持することも多くのリソースを必要とします。
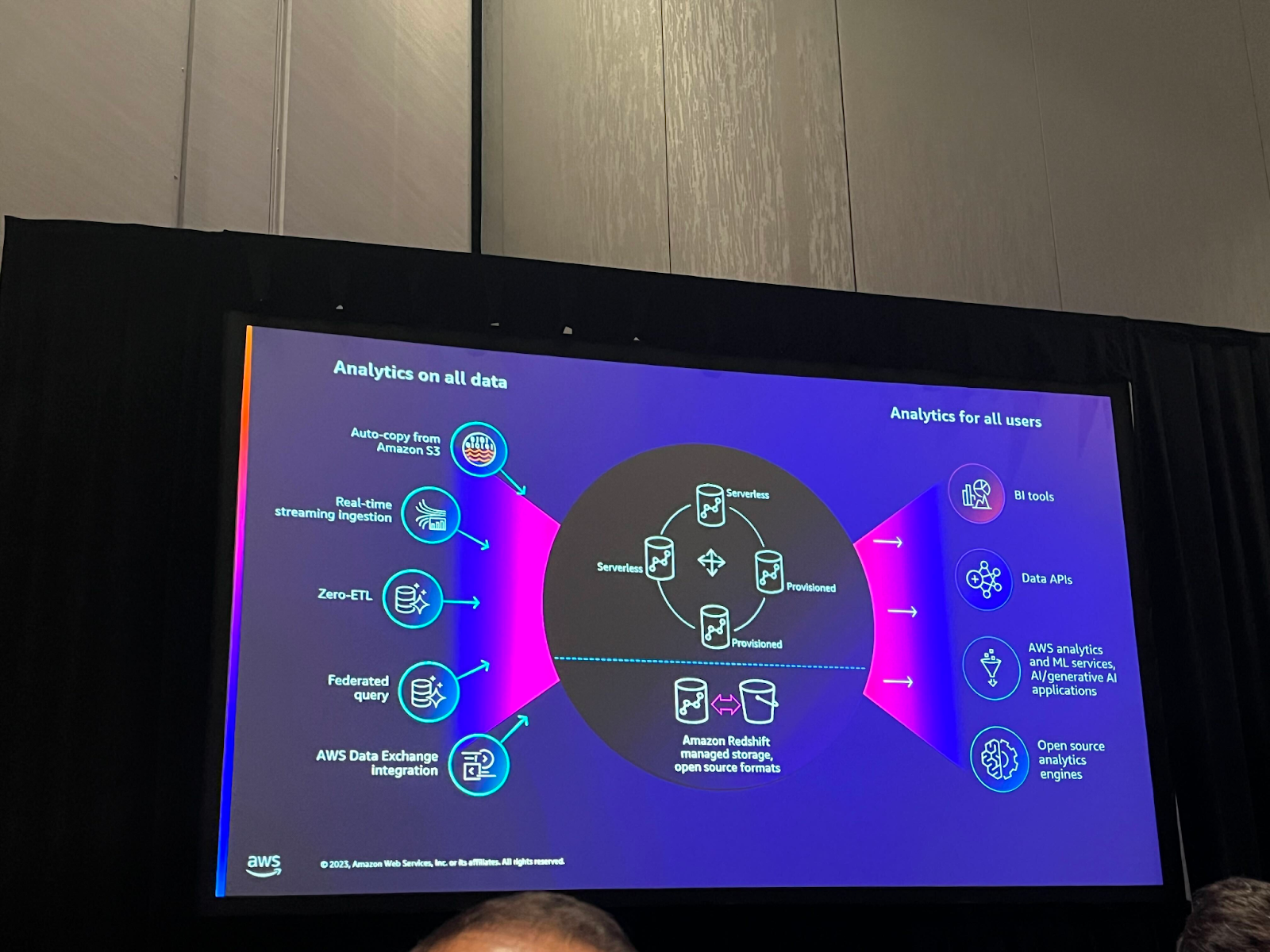
このため、AWSではETLをより簡単にできるサービスと機能を提供しています。
この章の表で左側はデータソースを準備するサービスと機能を示しており、右側はデータを分析して消費するサービスを示しています。下記のような機能とサービスを通じてETLプロセスの効率を高めることができます。
・Auto-copy: Redshiftへのデータコピーを自動化し、このような複製作業をスケジューリングします。
・Zero-ETL: Aurora MySQLとの連動が正式リリース及びAurora postgre、RDS mysql及びDynamo DB previewをリリース。
・Data Exchange Integration: Redshift Data Exchange機能を活用し、他のアカウント間のデータを簡単に共有することができます。これにより、コンシューマーが簡単にデータを共有し、2つの組織間のデータ共有が容易になります。
Data Lake and Data Warehouse Architectures

データレイクは様々なフォーマットの生データを保存する中央ストレージの役割を果たし、データレイクにデータを保存することでコスト最適化にも役立ちます。 データウェアハウスは、高速性能と低レイテンシーに基づく準リアルタイムレポートが必要な場合に使用します。主に複雑な集計やビジネスロジックの実装に適しています。
Redshift Integration with Data Lake

Redshiftは継続的に発展しており、様々なサービスとの連動のための様々な機能を提供しています。
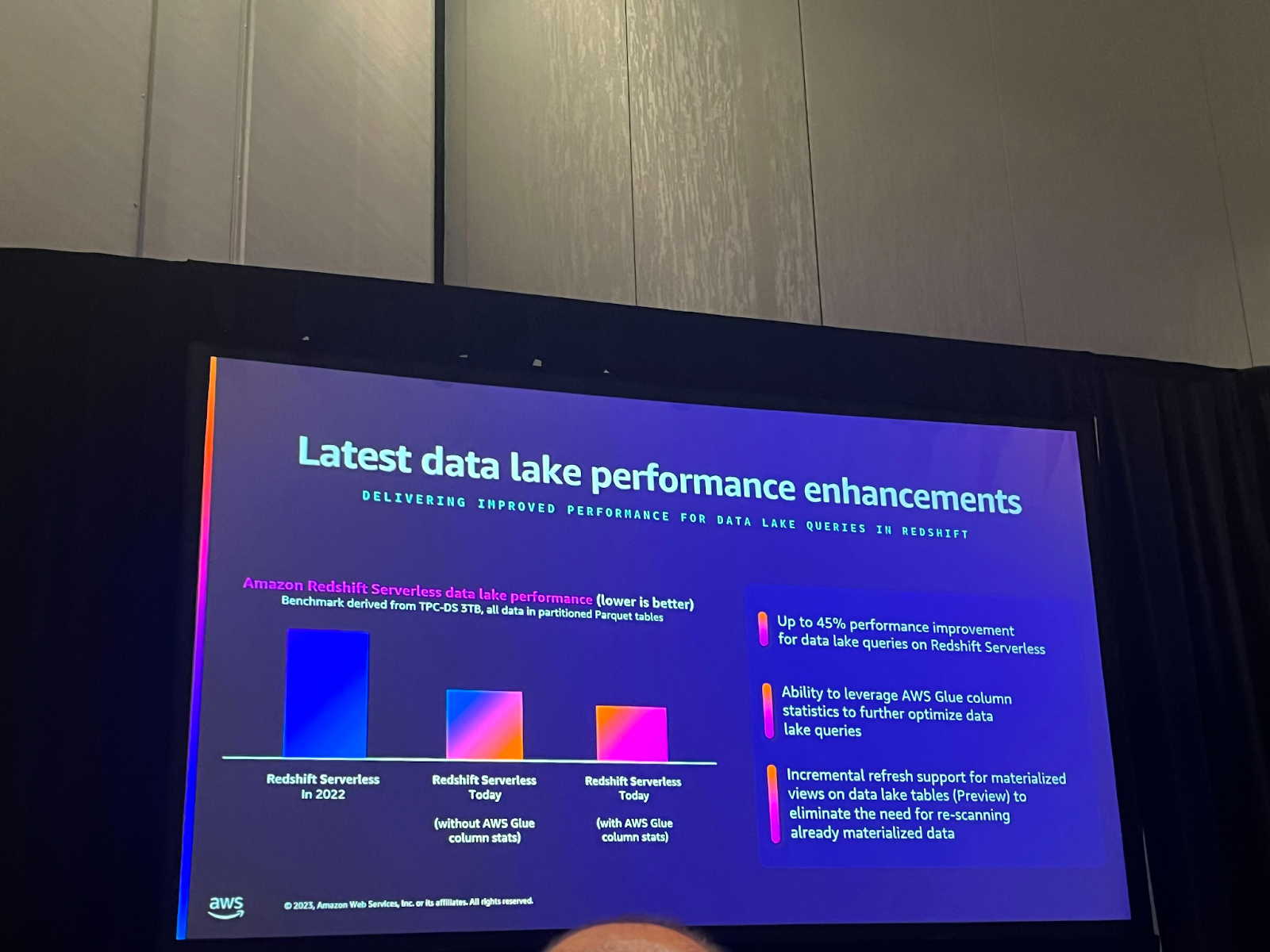
データを分析する上でパフォーマンスは最も重要な要素であり、AWSは継続的にRedshiftのパフォーマンスを改善するために投資してきました。表内の最初の指標と2番目の指標を比較すると、Redshiftのパフォーマンスは昨年に比べて最大45%向上しました。 さらに、新しく発表された機能であるGlue column statsを活用し、glue column statisticsを基にクエリを計画することで、データレイククエリを最適化することで、さらにパフォーマンスを改善しました。
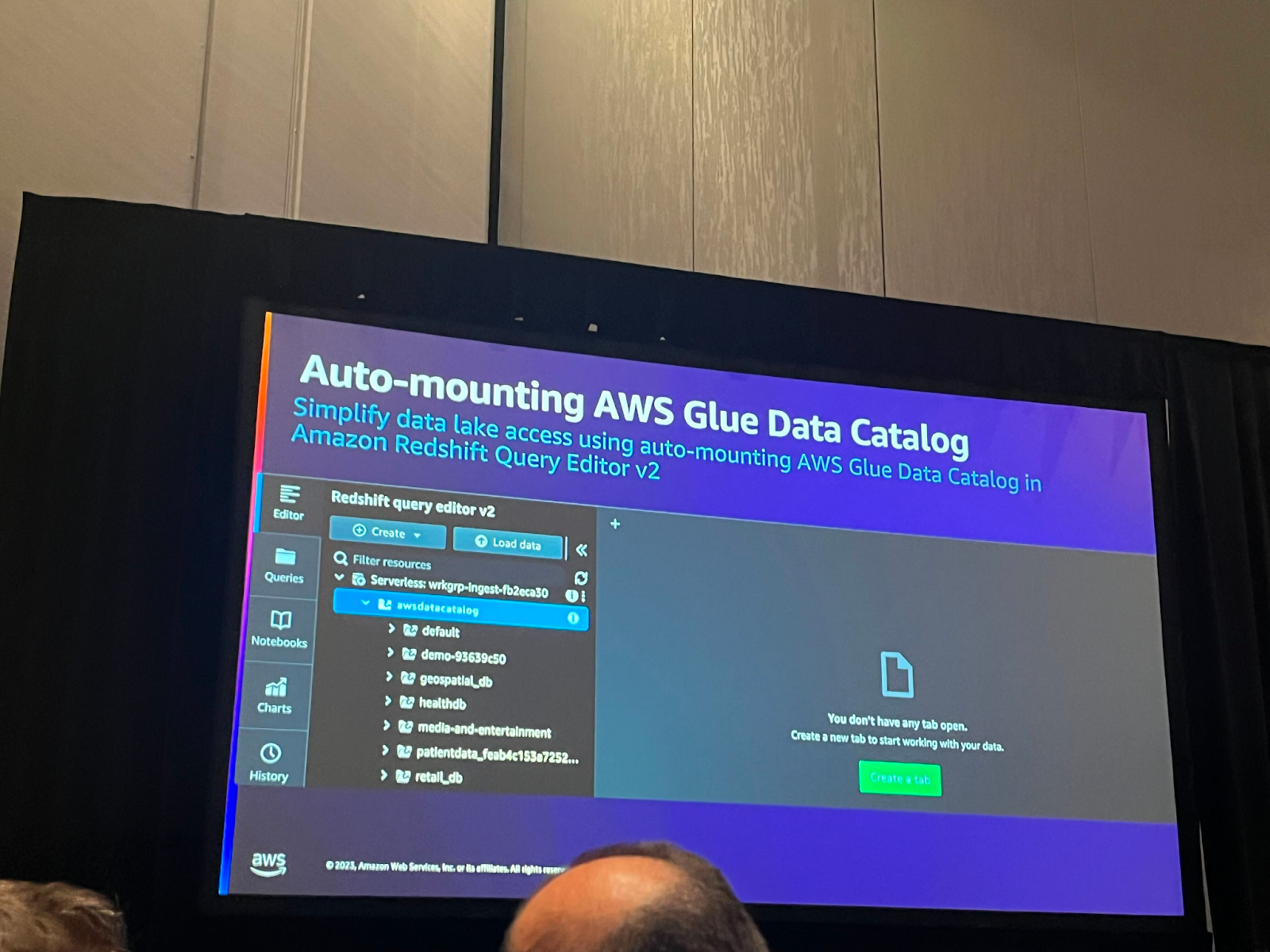
Redshiftでデータレイク内のデータに対して便利にクエリを実行できるAuto-mounting Glueデータカタログがリリースされました。 これで、Redshift内でGlueデータカタログを使用するために別途外部スキーマを作成する必要がなくなりました。

Auto-copy機能を活用すれば、low codeベースでデータingestionが可能で、重複データの読み込みを防ぐことができます。この時、コマンド実行やスキャン関連費用は発生せず、ストレージ費用が追加された分だけストレージ費用が発生します。しかし、Redshiftサーバーレスの場合、copy jobが実行されるとコンピューティングが必要なので、この時にサーバーが実行されます。
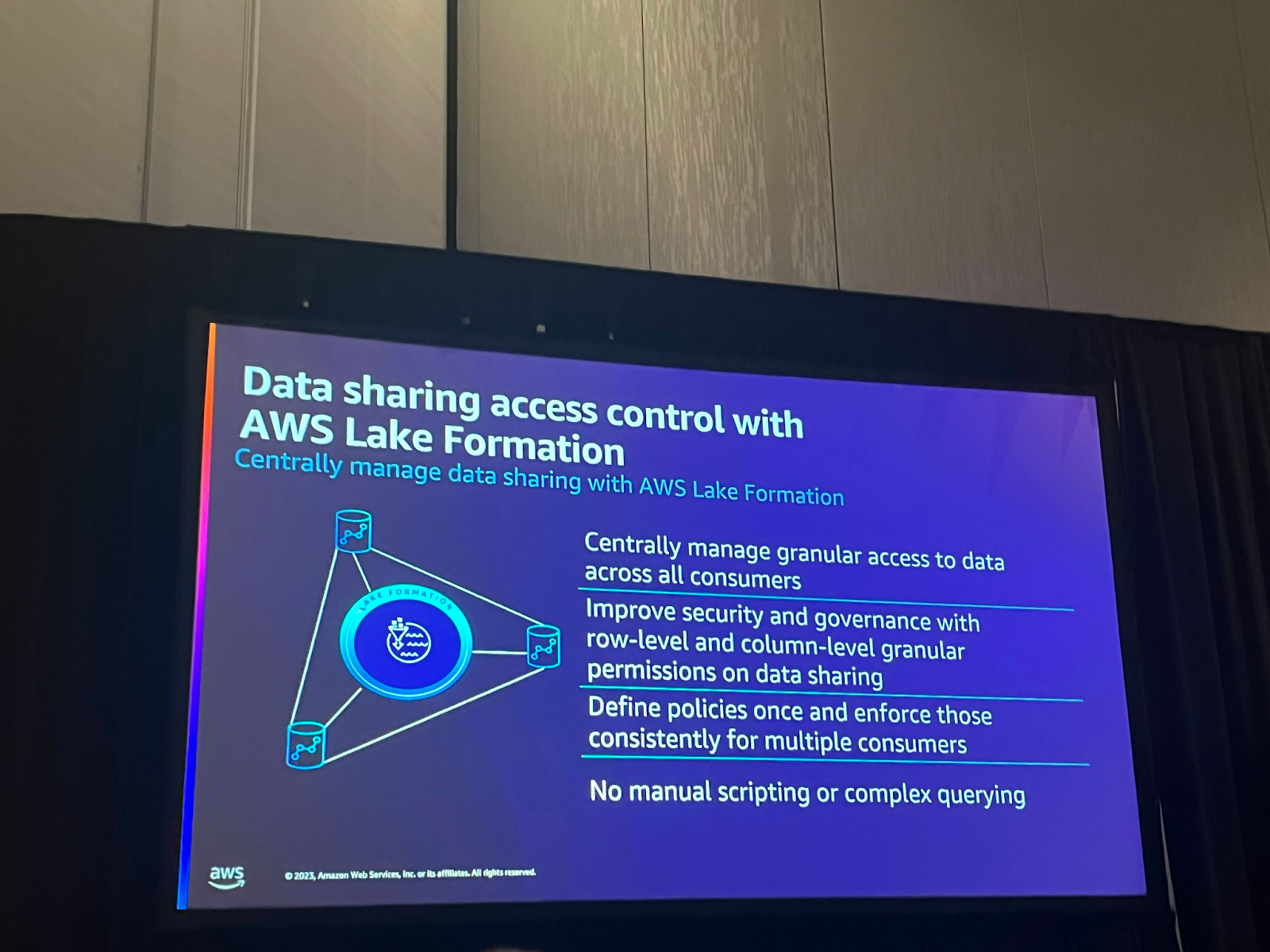
Lake FormationでRedshiftデータも管理できるようになりました。リクエストが多かった機能の一つですが、Redshiftデータを共有する際にもLakeFormationでcolumn-level、row-levelで細かくアクセス制御が可能です。

Glue catalogがマルチエンジンビューに対応しました。Glue catalogでビューを作成すると、Athena、Redshiftなどの他のエンジンでもクエリを行うことができます。様々なエンジンで使用するためにそれぞれのビューを作成する必要がなく、Lake Formationで便利にアクセス制御が可能になりました。
セッションを終えて
以上、Redshiftの様々な新機能を紹介しましたが、Redshiftが他のAWSサービスとの連動がより簡単になることで、AWS上のデータパイプライン構築がより便利で拡張性が向上することが確認できました。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner