MEGAZONEブログ

Building a practice to optimize your customer’s resilience journey
顧客のレジリエンス・ジャーニーを最適化するためのプラクティスの構築
Pulisher : Enterprise Managed Service Group ワン・ヒョンシク
Description : AWSのレジリエンスとディザスタリカバリのための様々な方法についての紹介セッション
はじめに
様々なワークロードの環境でインフラを運営中、システムまたはヒューマンエラーにより、様々な原因による障害が発生する可能性があります。障害発生時、迅速な復旧後のサービス正常化が要求されますが、今回のセッションを通じて、復旧過程でより安定的で正確な手順で実行できるノウハウを習得したいと思います。
セッションの概要紹介

1時間、AWSのレジリエンスについて、レジリエンスを定義する方法、お客様のレジリエンスについて話す方法、そしてパートナーと一緒に、私たちが市場で見ていること、お客様と協力する際に見ていること、私たちが支援する方法について話します。
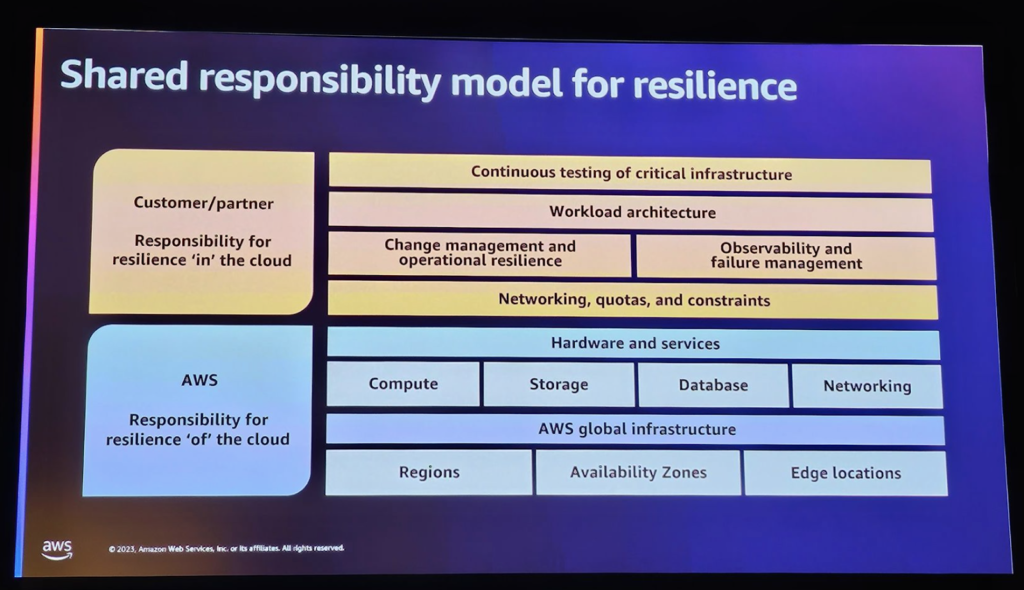
米国では、顧客のワークロードの場合、セキュリティと非常によく似た共同責任があります。これは、AWSがクラウドのレジリエンスを担当するように、サービスやグローバルインフラストラクチャ、または可用性の領域を担当するような、レジリエンス、責任共有モデルです。レジリエンス、観測可能性、その他多数。
このモデルで注目すべき点は次のとおりです。
・顧客側には多くの責任があります。
・顧客とレジリエンスについて話すとき、顧客とパートナーのサポートが非常に必要です。

AWSがITのレジリエンスを定義する方法は、インフラストラクチャやサービスの中断から回復するワークロードの能力に合わせて調整することです。 これは、需要を満たし、誤った構成や一時的な問題によって発生する可能性のある中断を緩和することです。 これがAmazonの公式定義です。回復力とは、ダウンタイムの期間と影響を最小限に抑えることだと考えています。

システムが稼働していない時間もコストがかかります。収益、ブランド価値、生産性、そして法規制などがコストを決定するのに主要な影響を与える要素です。

パートナーは次のような役割を果たすことができます。
・移行、設計、運用、管理
・ビジネスコミットメントの構築、エクセレンスセンターの構築、知識および技術的な準備の維持
・技術的な観点からのチームトレーニング、マーケティングの観点からのレジリエンスを適用する。
・レジリエンスを中心とした製品のサポートとリリース

ビジネス関係とは、コンサルティング、Managed-Service、技術的なサポートなどを協力することを指します。
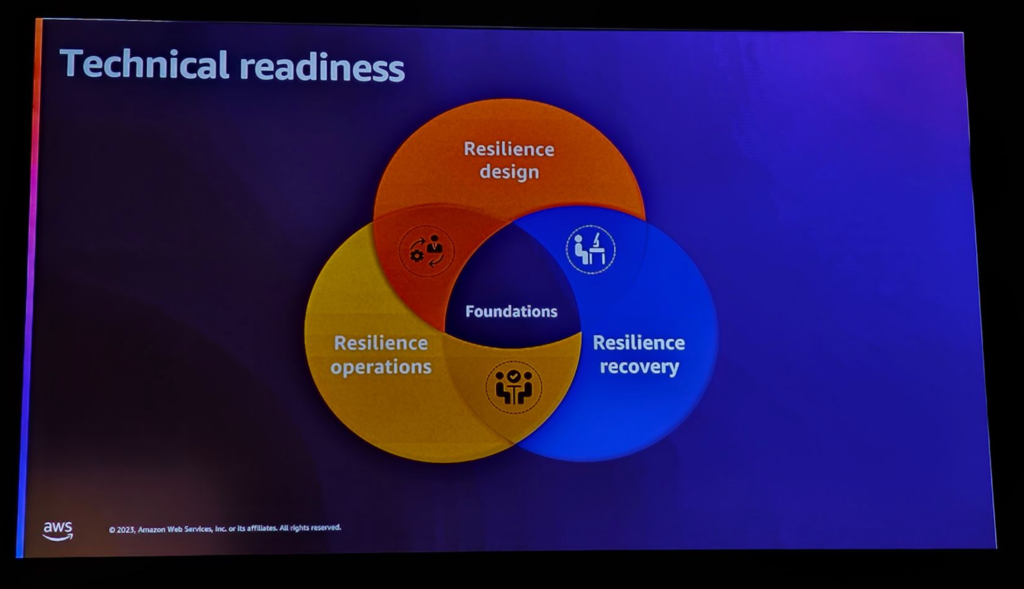
技術的な側面から見ると、弾力性を4つの構成要素に分けることができます。
1.基盤
・お客様のビジネス要件を理解し、リスクを評価する
・RPO(Recovery Point Objective)とRTO(Recovery Time Objective)を設定します。
2.設計
・アプリケーションを柔軟に設計する
・ディザスタリカバリ計画の策定
3.運営
・システムのモニタリングとイベント対応
・運用チームの教育
4.監視機能
・システムの監視と性能測定
・ユーザーエクスペリエンスの理解

マイクロサービスに投資し、近代化に投資することをお勧めします。 その理由は、毎月の失敗にも優先順位があり、少なくともユーザーエクスペリエンスでは、部分的な失敗は全体的な失敗よりも優れているからです。 マイクロサービスはこれらのことを可能にし、アプリケーションにできるだけ多くの労力をかけるこれらのマイクロサービスを適用することが重要です。
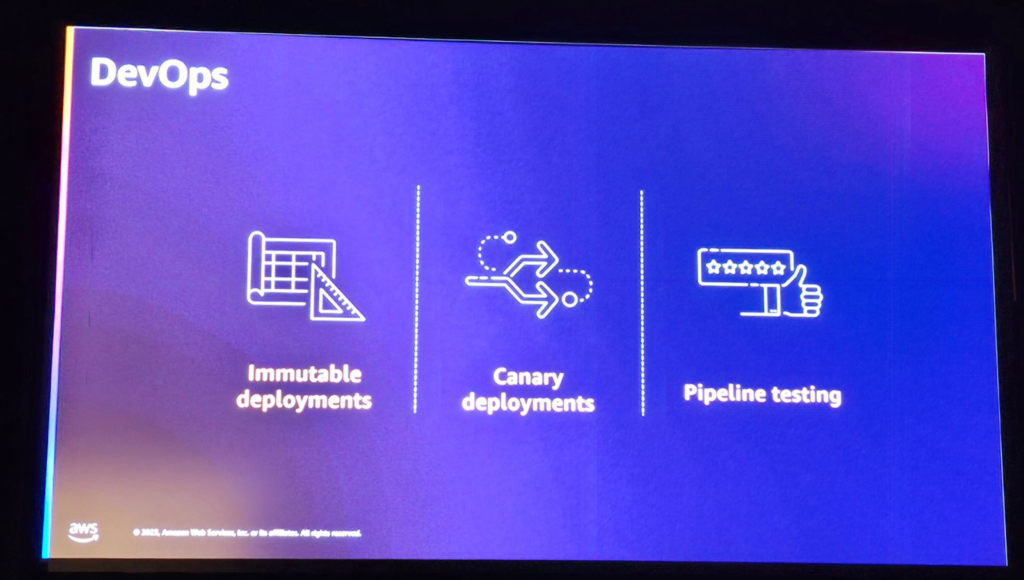
DevOpsのメリット
・コード化された変更のみを可能にすることで一貫性を確保します。
・Canaryデプロイメントを使用して変更を安全にデプロイすることができます。
・すべてのテストをパイプラインの一部として含めることで、本番環境にプッシュされる前にすべての欠陥を特定します。

データ主権、コンプライアンス、またはディザスタリカバリのためにMulti-Regionを使用
・データ主権とは、データが特定の国または地域でのみ保存されることを要求することです。
・コンプライアンスは、特定の規制を遵守する必要があることを意味します。
・ディザスタリカバリは、災害発生時にアプリケーションを継続的に使用できるようにするための要件です。 これらの要件を満たすために、アプリケーションを複数の地域に展開することができます。

高可用性とリカバリの設計と実装について、以下のようないくつかのアドバイスを提示しました。
ソフトウェア開発ライフサイクル(SDLC)にいくつかの追加機能を含める
・リトライ: データベースやその他のリソースが使用中であれば、数秒後に再試行します。
・パフォーマンスリミット:システムが事前に合意されたパフォーマンスレベルを超えないように制限します。
・サーキットブレーカ: サービスの中断が他のサービスに影響を与えないようにします。
段階的な防御コンポーネントを実装
・ロケーションへのデプロイメント: アプリケーションを複数の地域にデプロイします。
・高可用性のための自動フェイルオーバー:システムコンポーネントが故障した場合、自動的に復旧します。
・ディザスタリカバリ:災害発生時にシステムを復旧できる計画を策定します。
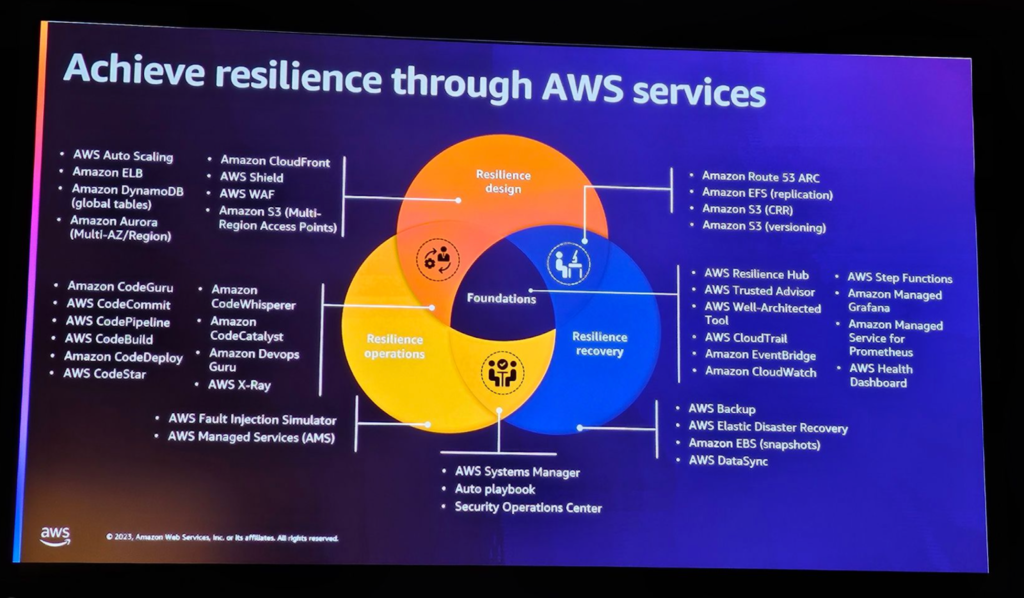
AWSが提供するサービスのうち、レジリエンスを実現するデザインについて、以下のように整理することができます。

Amazonはレジリエンスを改善するための様々なサービスを提供しています。
・AWS Resilience Hub: アプリケーションのレジリエンスレベルを評価し、改善するためのツールです。
・AWS Disaster Recovery Service (DRS): 仮想マシン、物理サーバー、ワークロードの保護と復旧を支援するサービスです。
セッションを終えて
今回のセッションでは、レジリエンスとディザスタリカバリのための様々な方法を紹介しています。 特に、レプリケーション、自動フェイルオーバー、段階的防御などの方法を適用するために、マイクロサービスベースのアプリケーションを積極的に活用することを推奨することは、実際に多くのお客様に適用できる部分です。 また、金融サービスのお客様は、安定性が重要な特性があります。このような場合、マイクロサービスを通じて、特定のアプリケーションが故障しても、他のマイクロサービスがそのマイクロサービスに代わってシステムの可用性を維持できるようにすることができます。 また、レプリケーションを通じてマイクロサービスを複数のポイントに複製し、障害時にもアプリケーションを使用できるようにすることができると考えられます。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner