MEGAZONEブログ

AWS re:Invent 2024 セッションレポート #STG207|Amazon S3 Glacierストレージクラスでコールドデータの価値を最大化しましょう
Maximize the value of cold data with Amazon S3 Glacier storage classes
セッション概要
- タイトル:Maximize the value of cold data with Amazon S3 Glacier storage classes
- 日付:2024年12月3日(火)
- Venue:MGM Grand | Level 1 | Grand 120
- スピーカー:
- Gayla Beasley(Sr. Technical Program Manager, Amazon Web Services)
- Andrew Pohl(Sr. Manager, Product S3, AWS)
- 概要:Amazon S3 Glacierストレージクラスを活用して、コスト効率よくデータストレージをモダライズし、高価なテープドライブやオンプレミスのストレージの心配をなくす方法をご紹介します。 このセッションでは、ペタバイト規模のデータを保存および復元し、コストと検索パフォーマンスを最適化するオプションについて説明します。
はじめに
今回のAWSテクノロジーセッションに参加した理由は、データの保管とコスト効率の重要性がますます大きくなっている状況で、最近担当するプロジェクトの一部のアカウントでコールドデータの管理方案について議論されたことがあり、関心を持って申請することになりました。 Amazon S3 Glacierは、ストレージクラスを活用してコールドデータを効果的に管理する方法と、コストを削減し、データの価値を最大化する方法を学ぶことを期待しています。
具体的には、データライフサイクルの管理と回復方法の実践的なケースで、洞察を得るために申請することができました。
Cold Dataの重要性

Cold Dataは、四半期ごとに1回以下にアクセスするデータを指しますが、世界中のデータの約70~80%がCold Dataに分類され、長期的に保存が必要です。 Cold Data を保存する主な目的は次の 3 つです。
- 保存(Preservation):将来の価値を考慮して保存するデータ(ex.ビデオ、画像)には、メディアファイル、データレイク内の過去のデータなど、長期的に利用可能なデータが含まれます。
- バックアップ:データ復旧に備えたストレージで、復旧時間の目標を満たしながらデータを保持する必要があります。
- コンプライアンス:法的要件に基づく長期保管データで、5年以上または恒久的にデータを保存する必要がある場合があります。
Amazon S3でコールドデータを保存する


AWS S3 はさまざまなストレージクラスを提供し、データアクセスの頻度に応じて最適化されたコストでデータを保存できます。主なストレージクラスは次のとおりです。
- Glacier Instant Retrieval:即時データアクセスが必要な場合は、医療画像やユーザー作成のコンテンツを保存するのに適しています。
- Glacier Flexible Retrieval:復元には数分から数時間かかりますが、費用対効果の高い、一括復元オプションを無料で提供しています。
- Glacier Deep Archive : 長期保管用ストレージクラスで最も安価なオプションで、データアクセス頻度が非常に低い場合に適しています.
AWS は、データにアクセスしにくい場合は、S3 のさまざまな Cold Data ストレージクラスに移動することをお勧めします。これは、データアクセスの頻度が減少するにつれてストレージコストを削減しますが、アクセスコストは増加するトレードオフを利用する方法です。
データライフサイクル管理とコスト最適化

Amazon S3 Lifecycle 機能を利用すると、データのアクセス頻度が低下するにつれて自動的にストレージクラスを切り替えることができます。たとえば、データを作成してから90日間はGlacier Instant Retrievalに保存し、その後180日目にはGlacier Deep Archiveに移動することでコストを削減できます。

AWS は、S3 Storage Lens と Storage Class Analysis を介してデータアクセスパターンを分析するためのツールを提供します。これにより、データの使用パターンを把握して適切なライフサイクルポリシーを設定できます。さらに、ライフサイクルの有効期限を使用して特定の期間以降にデータを自動的に削除することで、保存コストをさらに削減できます。これらの機能は、長期的にデータが不要になるまで、完全なデータ管理ポリシーを設定できます。
オブジェクトサイズフィルタ: デフォルトでは、128KB以下のオブジェクトは切り替えられず、大きなオブジェクトを中心に切り替えるとコスト削減効果が高くなります。
オブジェクトサイズ(Object Size):大きなオブジェクトであればあるほど、コストを削減でき、オブジェクトサイズが大きいほど損益分岐点までの時間が短縮されます。
バケットプレフィックスとタグ:データ構造に応じて、プレフィックスまたはタグに基づいてポリシーを適用できます。
Amazon S3 Glacier からのデータの復元

Glacierストレージでは、データの復元は次の手順3の手順に進みます。
- 復元要求の開始:復元時間とコストのニーズに応じて、緊急復元、標準復元、およそ復元オプションの中から選択できます。
- リストア完了の確認: リストアのステータスは、S3 コンソール、CLI コマンド、API、または S3 イベント通知で確認できます。
- 復元されたデータへのアクセス:復元されたデータはS3 Standardに一時的に保存され、既存のS3 APIにアクセスできます。

さ復元速度に応じて、次のオプションを選択できます。
- 緊急復元(Expedited Restore):1〜5分以内に復元します。
- 標準復元(Standard Restore):数分から5時間以内に復元されます。
- 一括復元(Bulk Restore):5〜12時間以内に復元され、最も費用対効果が高いです。

AWS は、1 秒あたり最大 1,000 の復元リクエストを処理できるバッチ操作 (Batch Operations) をサポートしています。この機能は大規模なデータを効率的に復元し、ジョブが失敗した場合の自動再試行と完了レポートを提供します。

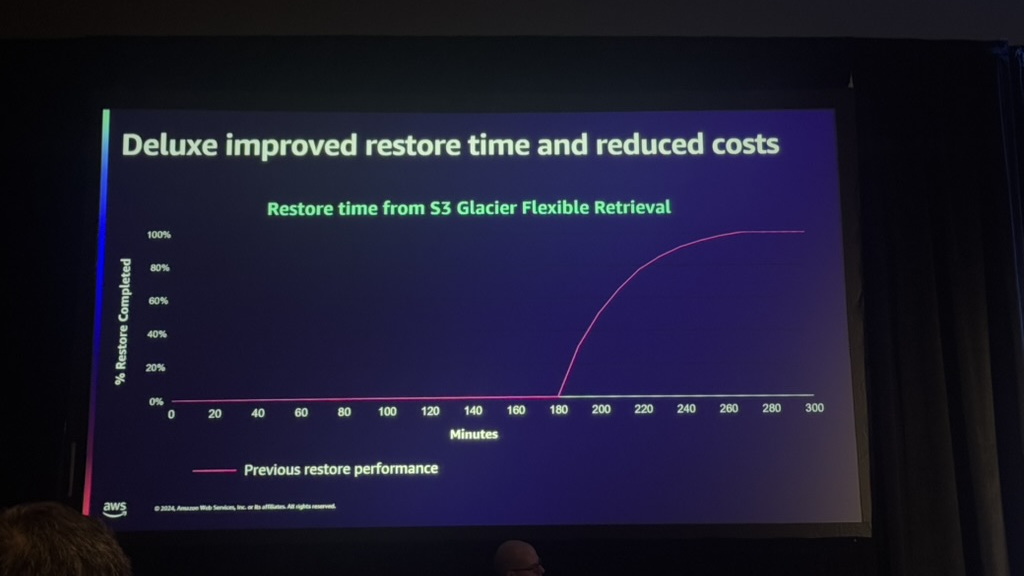
顧客の例としては、デラックスなどのメディア企業がバッチ作業を活用してデータの復元プロセスを簡素化し、コストを削減した例があります。 Deluxeは復元速度を数時間から数分単位で短縮し、コスト効率を最大化しました。
また、復元されたデータはデフォルトで一時的に保存されるため、必要に応じてデータを別のバケットに移動したり、新しく保存して長期保存ポリシーを設定したりできます。
Cold Dataの価値を最大化する主なポイント

そのセッションを終えながらCold Dataの価値を最大化する上で重要な要点をまとめると以下の通りです。
- Amazon S3 Glacier で低コストでデータを保存します。
- データ検索の要件に応じて適切なストレージクラスを選択してください。
- Cold Dataを使用して価値を生み出す方法を見つけます。
- S3 Batch ジョブを使用して大規模な復元ジョブを最適化します。
まとめ
今回のセッションでは、Amazon S3 Glacierを活用したCold Data管理の重要性と具体的な方法論を学ぶことができました。です。
AWSカスタマーケース(Canva、NASCAR、Deluxeなど)を通じて、実際に適用可能な戦略を特定し、定期的なデータ管理計画を確立する必要性を感じました。 S3 Lifecycleやバッチジョブなどの自動化機能を活用して、データの保存と復元プロセスを簡素化し、費用対効果を高めることが印象的で、データアクセスパターン分析ツールを使用してデータをより体系的に管理する方法学べました。
今回のセッション内容で学んだ内容に基づき、Glacier Deep Archiveのような低コストのストレージクラスをより積極的に活用してデータストレージコストを最小限に抑えるとともに、AI/MLなどの新しいデータ活用機会を探し、データストレージと活用のバランスをとり、実務に反映することを期待しています。
記事 │MEGAZONECLOUD Enterprise Managed Service Center(EMS) Cloud Engineer 6 Team ウォンミンジ
この記事の読者はこんな記事も読んでいます
-
 Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り
Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り -
 Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速
Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速 -
 Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び
Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び