MEGAZONEブログ

AWS re:Invent 2024 セッションレポート #CMP309|必要なのはRAG(Retrieval Augmented Generation)だけですか?
Is Retrieval Augmented Generation (RAG) all you need?
セッション概要
- タイトル:Is Retrieval Augmented Generation (RAG) all you need?
- 日付:2024年12月4日(水)
- Venue:Venetian | Level 3 | Murano 3201B
- スピーカー:
- Amogh Gaikwad(Sr. Solutions Developer, Amazon Web Services)
- Shane Thompson(Sr. Solutions Architect, Amazon Web Services)
- 概要:Generative AIの応答精度を高めるためにRetrieval Augmented Generation (RAG) とファインチューニング手法を活用する方法を学ぶことができます。Amazon Bedrock Knowledge Basesを使用してRAGを簡単に実装する方法、Amazon SageMakerからAWS Trainiumでモデルを最適化し、AWS Inferentiaでデプロイした後、Amazon OpenSearch ServiceでRAGワークフローを構築する方法を学びます。 各アプローチをユーザーのニーズに合わせて最適化する方法についても説明します。
はじめに
生成型AI応答の精度を上げる方法は?今回のワークショップでは、Retrieval Augmented Generation(RAG)と詳細調整(Fine-Tuning)を通じてこれを解決する2つのアプローチを取り上げます。
まず、Amazon Bedrock Knowledge Basesを活用してRAGを迅速に実装する方法を学び、その後Amazon SageMakerとAWS Trainiumでモデルを細かく調整した後、AWS Inferentiaでデプロイし、Amazon OpenSearch ServiceでRAGワークフローを構築する実習が進行になります。
各方法の特徴や適用時期を学び、実務に必要なツールやスキルを身につけることができると期待しました。
About LLM
大規模言語モデル(LLM)は、人間に似たテキストを生成するための単語シーケンスを予測する生成型AIモデルです。 LLMは2017年に発表されたTransformerアーキテクチャに基づいており、このアーキテクチャは「Attention is All You Need」論文で最初に導入されました。その後、大規模なトレーニングデータセットとパラメータを活用してモデルサイズが急速に拡大するにつれて、パフォーマンスが飛躍的に向上しました。
しかし、既存のLLMには次の制限があります。
- トレーニングデータに依存:モデルのパフォーマンスは事前学習されたデータに限定され、ドメイン固有の専門知識や最新情報は含まれないことがよくあります。
- 最新情報の不足:トレーニングデータの視点制限は、最近の情報やニュースデータを反映していません。
この制約により、LLMを実用的なビジネスワークロードに活用するには「カスタマイズ」が必要です。カスタマイズにより、ドメイン知識を追加し、特定のデータセットにモデルを適応させ、より正確で信頼性の高い結果を導き出すことができます。
カスタマイズ LLM
LLM をビジネスに合わせて最適化するには、さまざまなカスタマイズ方法を使用できます。各方法は、目標と必要に応じてパフォーマンス、時間、コストの点で異なる方法で適用できます。このセッションでは、最も一般的なカスタマイズ技術であるプロンプトエンジニアリング、情報検索エンハンスメント生成(RAG)、ファインチューニング(Fine-Tuning)、およびモデル学習を比較して、どのような状況でどのような方法が最適かを学びます。

(1) プロンプトエンジニアリング
プロンプトエンジニアリングは、モデルに特定の入力を提供して所望の形式の出力を導出する方法です。これは簡単かつ迅速に適用できる技術で、ユーザーがモデルに提供するプロンプト(質問や指示)に従ってモデルの反応を調整できます。たとえば、質問に対する明確な回答を導いたり、特定のスタイルでテキストを生成したりできます。
【メリット】
簡単な設定で迅速な結果が得られ、モデルを再学習することなくすぐに使用できます。
【短所】
複雑またはドメインに特化したビジネスニーズには限界がある可能性があります。特に、モデルが理解できる範囲内でのみ応答するため、モデルの深い理解が必要な問題には適していません。
(2) 情報検索増強生成(RAG)
RAGは、外部データをベクトル形式でインデックス化し、モデルが特定のクエリまたは要求に関する関連情報をリアルタイムで取得し、それに基づいて応答を生成する方法です。これを行うには、ベクトルデータベースを使用してドメイン関連データを埋め込み(ベクトル化)し、クエリが入るとそれに関連するデータを検索してモデルに提供します。このモデルは、既存の訓練されたデータに加えて、リアルタイムで更新された情報に基づいて応答を生成するので、応答の精度と信頼性を高めることができます。

【メリット】
外部データをリアルタイムで反映することができ、最新情報やドメイン特化した知識に対する精度が高まります。
【短所】
データの取得と提供には時間がかかり、適切なベクトル化とデータ管理が必要です。さらに、誤ったデータが提供された場合、結果の精度に影響を与える可能性があります。
(3) ファインチューニング(Fine-Tuning)
ファインチューニングは、事前トレーニングされたモデルのパラメータを調整して、特定のドメインまたはユースケースに最適化されたパフォーマンスを発揮させるプロセスです。既存の学習モデルに基づいて、追加のデータセットを使用してモデルを再学習することで、ドメイン固有の知識やユーザーのニーズに合った結果を提供できます。たとえば、医療、金融、法律などの特定の業界に適したデータを使用して、モデルの理解を高め、より正確で具体的な対応を作成できます。

【メリット】
特定のビジネスドメインに合った非常に具体的で正確なモデルを作成することができ、データが十分に品質が高いとパフォーマンスが大幅に向上します。
【短所】
多くのデータと時間が必要であり、これにはかなりの計算リソースとコストがかかります。さらに、モデルパラメータを変更しながら既存のパフォーマンスに影響を与える可能性があるため、慎重なアプローチが必要です。
AWS Inferentia 2
AWS は、Inferentia と Trillium と呼ばれるカスタム AI アクセラレータを使用して、より最適化されたパフォーマンスを提供します。同時に達成できるように支援します。

- Inferentia 2
Inferentia 2は、AWSの第2世代AIアクセラレータです。モデル推論の効率を最大化し、高性能推論を提供するために必要な大規模メモリと高速データ処理速度をサポートします。- 4倍の高スループットと10倍の低遅延時間を提供
- 10TB/sのメモリ帯域幅と384GBのアクセラレータメモリ
- 175億パラメータモデルを単一インスタンスでデプロイ可能
GPUと比較して低コストで大規模なモデルを処理でき、モデル展開コストと計算リソースを半分に削減します。
WorkShop
データのロードと埋め込みを行った後、VectorDB(Redis)にロードします。
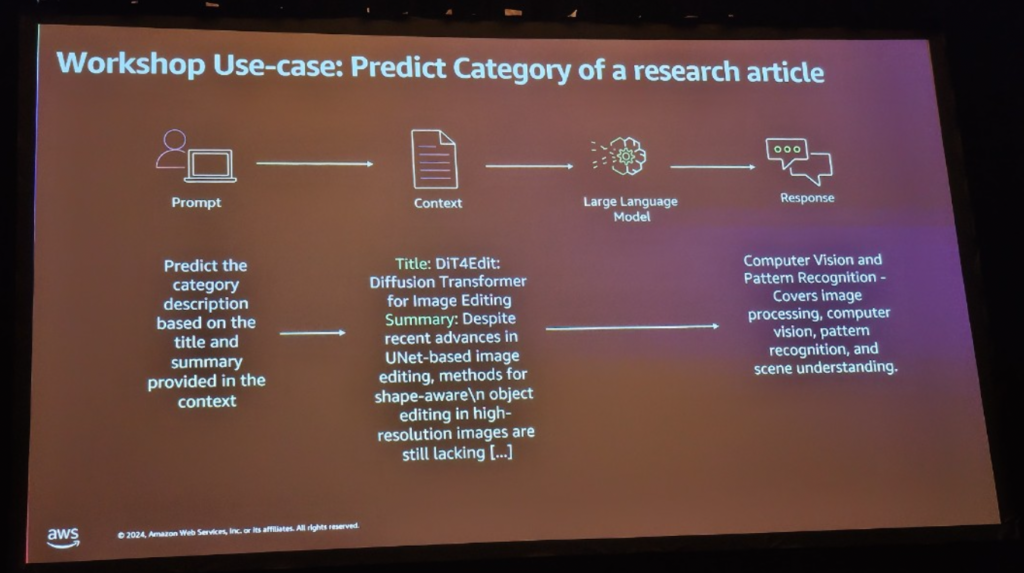
- 概要
このワークショップは、AWSのクラウドインフラストラクチャを活用してLLMを効率的にデプロイおよび運用する方法を学ぶことです。
- 利用サービス
- Amazon SageMaker: AWS の機械学習プラットフォーム
- AWS Inferentia 2: AI モデルを実行するための専用ハードウェア
- Amazon S3: モデルファイルを保存するストレージサービス
- 実践コース: Deploy Fine-Tuned Model on AWS Inferentia 2
- 必要なSDKとライブラリをインストールします。
- S3からモデルをインポートします。
- SageMaker ImageとModel ArtifactをインポートしてSageMaker Endpointを作成します。
- EndpointをInferentia2に展開し、推論テストを行います。
まとめ
このセッションでは、RAGとFine-Tuningを活用したLLMカスタマイズ技術について説明しました。 AWS InferentiaやAWS Trainiumなどの最適化されたハードウェアを使用してモデルのデプロイと推論効率を最大化できることを学びました。構築する経験が得られました。
セッションで学んだことにより、RAGとFine Tuningの使用時点をよく把握でき、特にAWSハードウェアリソースを最適化して効率的なコスト管理が可能であることが非常に有益でした。あったことが良かったし、Promptingも何度もテストをしてみて最適なプロンプトを探す過程が楽しかったです。
記事 │MEGAZONECLOUD AI & Data Analytics Center(ADC) Data Architecture Team チョ・ミンギョンマネージャー
この記事の読者はこんな記事も読んでいます
-
 Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り
Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り -
 Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速
Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速 -
 Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び
Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び