MEGAZONEブログ

AWS re:Invent 2024 セッションレポート #AIM353|Amazon Bedrockとオープンソースフレームワークを使用したエージェントの評価
Agentic evaluations using Amazon Bedrock and open source frameworks
セッション概要
- タイトル:Agentic evaluations using Amazon Bedrock and open source frameworks
- 日付:2024年12月2日(月)
- Venue:Wynn | Convention Promenade | Margaux 1
- スピーカー:
- Prem Ranga (Principal GenAI/ML Specialist SA, Amazon Web Services)
- Chad Hendren(Principal Solutions Architect、AWS)
- 業種:Cross-Industry Solutions
- 概要:このCode Talkでは、Amazon Bedrockとオープンソースのフレームワークを活用して、大規模言語モデル(LLM)で構築されたエージェントアプリケーションの評価について詳しく説明します。参加者は、検索拡張生成(RAG)、パイプライン、エージェント評価、LLMアプリケーションのデバッグ、テスト、評価、および監視のための統合プラットフォームであるLangSmithなどの概念についての洞察を得ることができます。この講演では、開発ライフサイクル全体にわたって、品質、コスト、遅延時間などのパフォーマンス指標を評価するための技術について説明します。また、検索、要求の品質、および全体的なアプリケーションのパフォーマンスを評価する際に、LLM審査員とエージェント指標の役割を強調し、参加者が強力で信頼できるエージェントソリューションを構築できるようにします。
はじめに
Amazon Bedrockは、単一のAPIでさまざまなLLMを提供し、RAG、エージェント、ツールなどを介して効果的なタスクを実行できるようにするサービスです。 Amazon Bedrockの機能には、モデルカスタマイジングの提供、ファインチューニング、RAGなどがあり、さまざまにサポートしています。セキュリティとプライバシーも重要な要素として扱われ、ガードレールなどの関連機能も提供します。今回のセッションでは、Bedrockのさまざまな機能のうちLLMとAgentsを活用し、LangSmithを使ったEvaluationまで進めてみました。
セッション概要
このコードトークでは、Amazon Bedrockとオープンソースフレームワークを活用して大規模言語モデル(LLM)で構築されたエージェントアプリケーションの評価について詳しく説明します。
参加者は、検索拡張生成(RAG)、パイプライン、エージェント評価、LLMアプリケーションのデバッグ、テスト、評価、および監視のための統合プラットフォームであるLangSmithなどの概念についての洞察を得ることができました。
この講演では、開発ライフサイクル全体にわたって品質、コスト、遅延時間などのパフォーマンス指標を評価する技術を調べ、検索、要求品質、および全体的なアプリケーションパフォーマンスを評価する際のLLM審査員とエージェント指標の役割を確認し、強力で信頼性の高いエージェントソリューションを構築するための知識を共有しました。
Amazon Bedrock
Amazon Bedrock は、基本的に、生成型 AI を活用する際に、単一の API を通じて多数の Foundation Model を活用できるようにするサービスです。また、モデルのカスタマイズとファインチューニングに関連する機能も含まれており、Knowledge Baseを介したRAG機能もサポートしています。これに加えて、Tool、Agentsを組み合わせてRAGだけでなく、他のリアルタイムデータを活用した推論まで可能にする機能をサポートし、Guardrailsなど様々な方法を通じて機密情報や有害性コンテンツ露出最小化、データセキュリティおよびガバナンス制御による安全性を提供します。

現在、100以上の異なるFoundation Modelへのアクセスを提供しており、生成型AIの発展に合わせて日が経つにつれ、ますます多くのモデルをサポートしています。
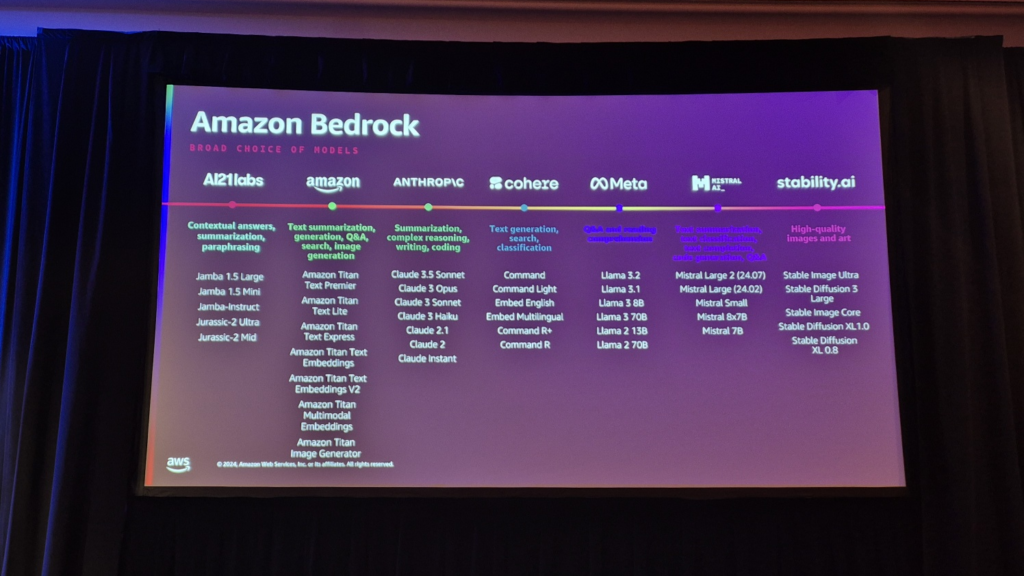
Bedrock Agents and Tools
複数のエージェントを組み合わせて、特定のビジネスケースに適用してトラブルシューティングすることもできます。一般的な生成型AIが学習またはRAGされたデータを介して回答するように、Agentsを介してリアルタイムでEC2インスタンスのステータスを確認するなど、追加の作業が可能です。
ToolとAgentsの概念を簡単に説明するには、Toolは特定の機能をするAPIを呼び出すFunction、Agentsはこれらの関数のいくつかを特定の目的のために組み合わせて結果を出すように組み合わせたモジュールだと考えれば良い。
例えば、目的地に向けたルート推薦サービス(一種のナビゲーション)を構築する場合、リアルタイム交通情報APIを呼び出すTool 1、距離や燃費に応じた油流比計算Tool 2、その他のアルゴリズムもしくはAPIで動作するTool 3などが体系的に編成され、「パスの推薦」という特定の目的を実行するためのエージェントを構成します。

デフォルトでは、AgentsまたはToolは次のように動作します。
- LLM に最初の照会を行う際に、LLM が利用できるさまざまな関数に関する情報を提供します。
- LLMは、ユーザーの要求を実行するために実行が必要な関数がどの関数であるかを推測し、その関数の名前を返します。
- このように返された関数名をコード段で解析して関数を実行し、その関数の実行結果をもう一度LLMに渡します。
- 必要なすべてのツールが実行され、結果が収集されるまで2、3回のプロセスを繰り返します。
- LLMは、ユーザーの要求に必要なすべての関数の結果が満足されたと思った場合、最終的な回答を生成して返します。
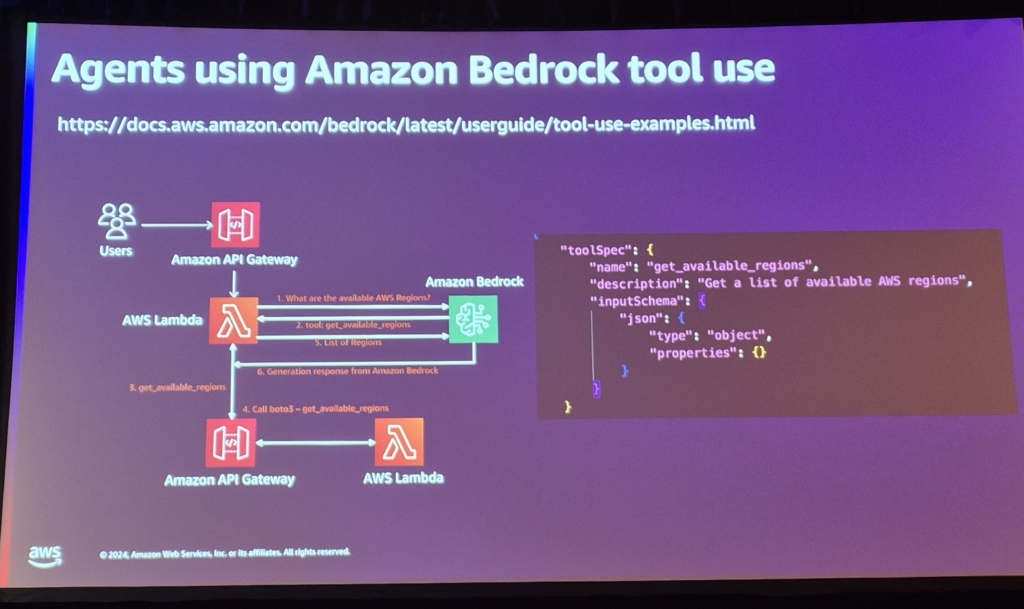
LangSmithを活用したAI評価
前述のように、LLMが動作してユーザーのクエリへの回答を返すまで、さまざまな手順を実行することができます。複数のツールが実行され、結果が返されます。また、これらのツールが集まった複数のエージェントを利用することもできます。一度の生成型AIアプリケーションの動作過程に無数の中間過程と結果が含まれています。
LangSmithは、これらの生成されたAIアプリケーションが実行される区間別のデバッグ、テスト、監視プロセスをサポートし、特に区間別の結果と遅延時間を特定して、アプリケーションの全体的なパフォーマンスを向上させるのに役立ちます。
まとめると、LangSmithはproduction-gradeのLLM Applicationをビルドできるプラットフォームで、AIシステムの性能を評価する目的で活用できます。 LangSmithを使用したEvaluationは、モデルの精度、処理速度、コストなど、さまざまな要素を定量的に分析するのに役立ちます。

LangSmithを使用すると、精度、Ground Truthなどの一般的な評価指標によるEvaluationだけでなく、特定のタスクを実行しながらstep-by-stepパフォーマンスチェックが可能になり、全体のプロセスが遅れるボトルネック現象を確認することができます。
さらに、評価者は直接トレースとモニタリングの結果を確認し、レビューし、フィードバックによる評価を通じて直感的なパフォーマンス評価を行うことに加えて、自動評価もサポートします。モデルの出力結果をLLM(評価対象LLM以外のモデル)を通じて品質をスコア化し、全体的な結果に対するクオリティチェックおよびフィードバックを行うことができ、特定の正規表現、キーワードなどによるルールベースの評価を進めることもできます。
LangSmithは、評価者が結果全体を追跡し、把握しやすいように、評価結果に基づいた可視化ツールを提供します。評価者は視覚化されたデータを使用して追加の段階的な評価が可能で、追加のチューニングポイントチェックが可能です。
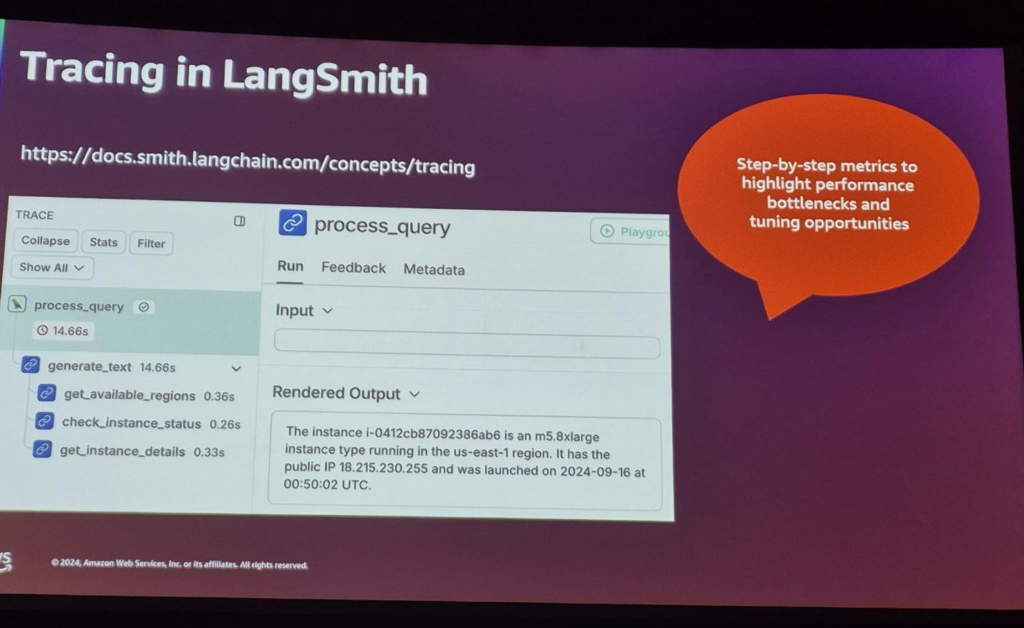
まとめ
Amazon Bedrock の Agents と Tool を活用して、生成型 AI のプロセスを進め、LangSmith を通じた全体のタスク監視と Evaluation をどのように進めるかを見てみました。実際に生成されたAI業務を進めてみると、最も重要と思われる部分の1つがプロセスが動作する区間別パフォーマンスです。 LangSmithを活用すれば、このような区間別トレーシングにより、遅延時間、コスト管理、ボトルネック現象緩和など様々な部分で改善していく余地を簡単に探索することができるようです。今回のセッションでは、Agentsを活用して既存に簡単に解決できなかった問題を様々な方法で実行することができ、複数のToolまたはAgentsが動作する過程でLangSmithを介した区間別トレーシングおよびモニタリングを通じてボトルネック現象チェックなどパフォーマンスを高めるために活用できるさまざまな方法を確認できました。
記事 │MEGAZONECLOUD, AI & Data Analytics Center (ADC), Data Engineering 2 Team、チョン・ジソン マネージャー
この記事の読者はこんな記事も読んでいます
-
 Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り
Compliance & Identity re:Invent2024 Security StorageAWS re:Invent 2024 セッションレポート #STG306-R|Amazon S3に対するセキュリティパターンについての深堀り -
 Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速
Cloud Operations Compliance & Identity re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #COP327|AWSベースの生成型AIの監査とコンプライアンスを加速 -
 Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び
Compliance & Identity Networking re:Invent2024 SecurityAWS re:Invent 2024 セッションレポート #NET205|集中型ネットワーク・トラフィック・インスペクション:重要な洞察と学び