MEGAZONEブログ

Apache Hudi on AWS:Tuning for cost and performance
AWS上のApache Hudi:コストとパフォーマンスのチューニング
Pulisher : Cloud Technology Center キム・ビョンジュ
Description:Hudiのパフォーマンス最適化に関するハンズオンセッション
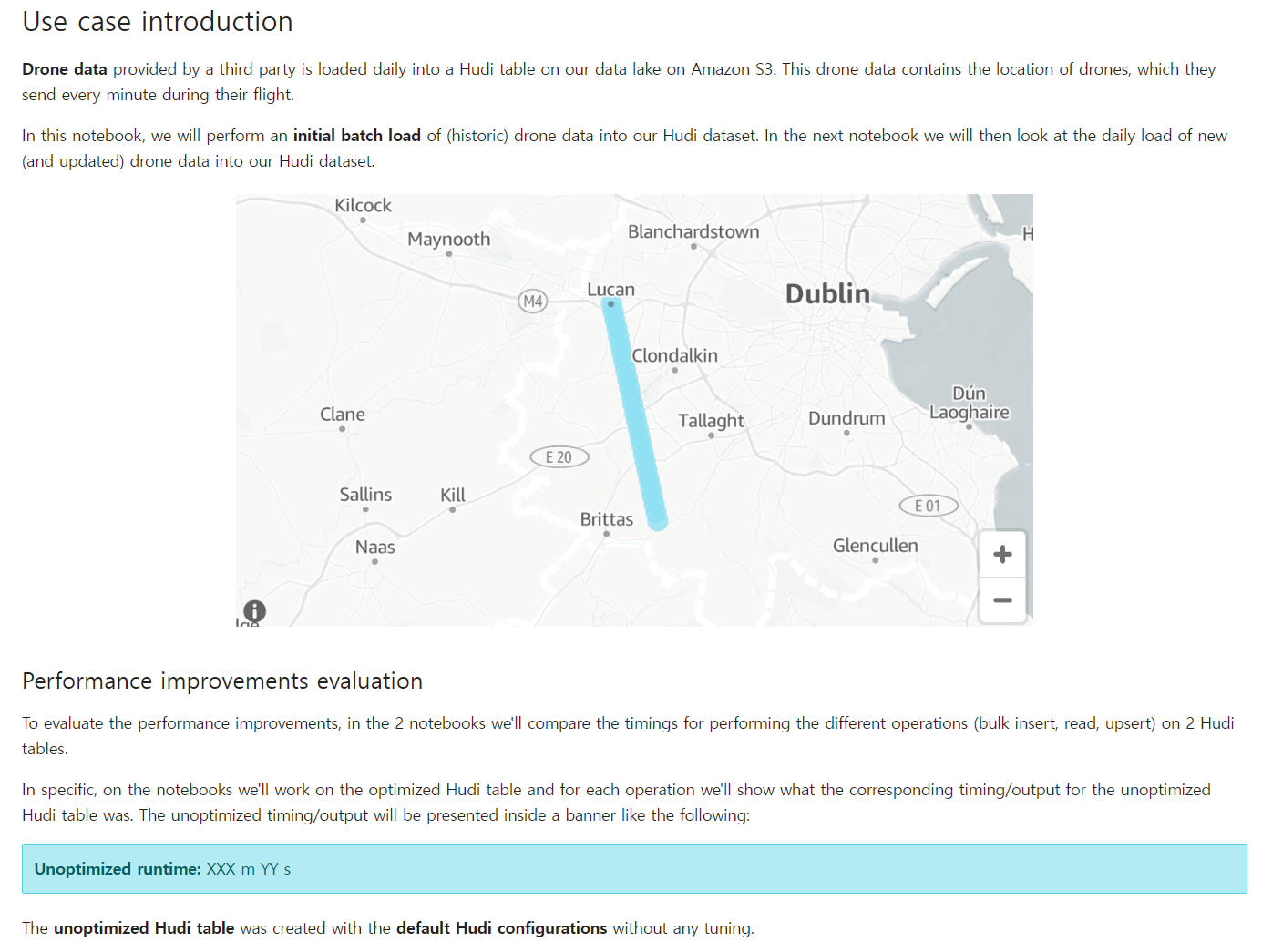
はじめに
Lakehouseとも呼ばれ、最近ではopenTable formatと命名する技術に対する関心が高まっています。
当然、これはビッグデータ分析分野で大多数の人が考えるHive Table Formatが管理が難しかったり、技術的に要件が満たされない(Update、Delete、ACID)など様々な理由から脚光を浴びています。
その中で代表的なOpenTable formatには3つ(Hudi、Iceberg、Delta Lake)がありますが、その中でHudiの性能最適化に関連したヒントを聞きたいと思い、このセッションを申し込みました。
セッションの概要紹介
このセッションはHands-On方式で行われましたが、時間的な制約のため、最適化されていないテーブルのテストは正確に行われませんでした。 ただし、先行してテストしていただいた結果を共有してくださったので、その指標を一緒に確認しながら進行しました。
サンプルデータはドローンデータを想定して作業を進めました。ドローンデータのTimestamp形式はyyyyMMddHHmmとなっており、当該ノートブックでは最適化されていない場合に下記のように表示されます。

当該テストを進行するのに使われたEMRは6.12バージョンであり、Hudiはv0.13.1で進行しました。EMRクラスターはマスター1台(r5.2xlarge、r5.xlarge、r5d.2xlarge、r5d.2xlarge、r5d.xlargeのいずれか)core node(worker node)は160vCPUが満たされる基準で作業しました。
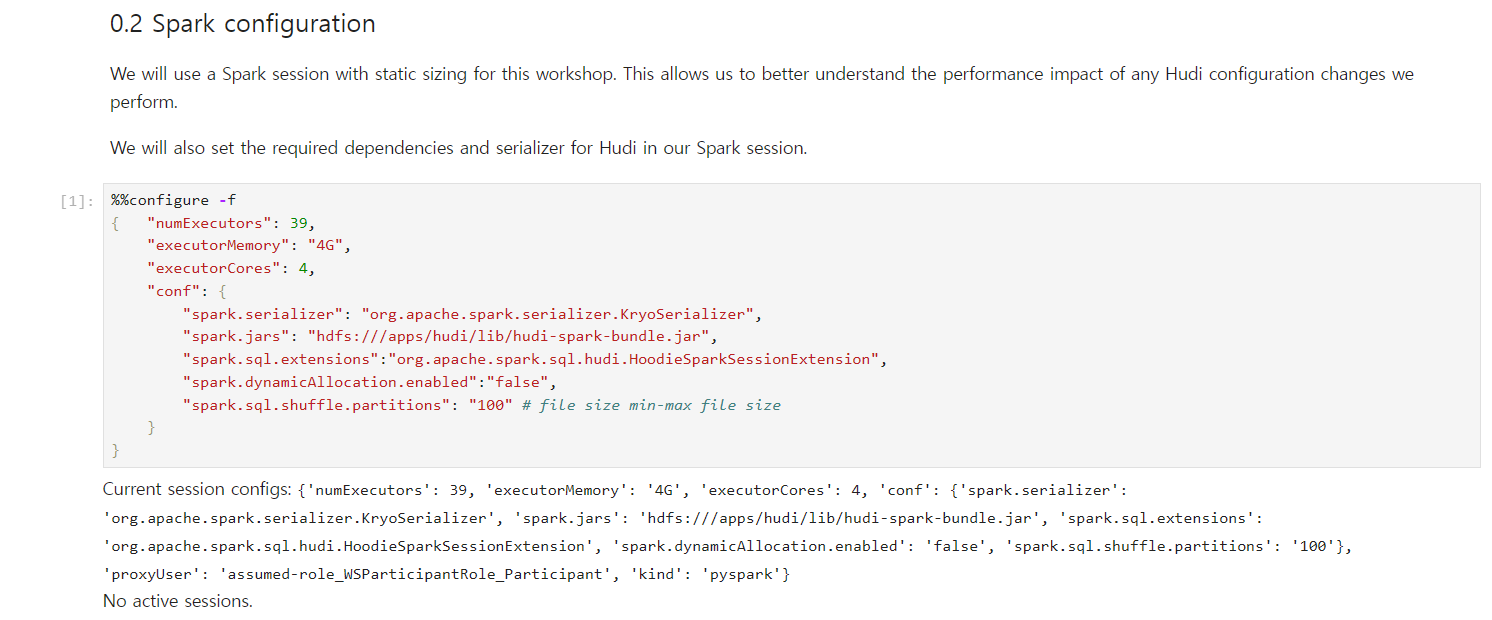
Spark sessionの設定は次のように進めたし、’spark.sql.shuffle.partitions’を使ってファイルサイズを調整する方式です(もちろん、他の設定値もありますが、一般的におすすめする一番簡単な方式だそうです)。
ソースデータはCSV形式のデータを読み込んで、スキーマの構造は次のような感じです(この記事ではノートブックソースの詳細な部分は載せず、結果中心で共有したいと思います)。

Icebergと違ってHudiには数多くの設定値が存在します。ただ、このような設定値をうまく扱うことができれば、状況によっては非常に良い性能を発揮します。

パーカーの基本的なパラメータ値を確認すると、以下のような様々なパラメータ値が存在することが分かります(あくまで基本です!)。ひとつひとつ簡単に説明すると、次のように説明することができます。
・hoodie.table.type : フーディーはCOW(COPY_ON_WRITE)、MOR(MERGE_ON_READ)二つの方法で保存することができます。ここで設定されたCOWを説明すると、例えば、Aバージョンのデータファイルに(a,b,c)カラムが含まれていて、updateやdeleteの過程でそのデータが変わる場合、Aバージョンのファイルをコピーして変更された内容をBバージョンのファイルに反映して管理する方法を意味します。
・hoodie.datasource.write.partitionpath.field : この部分はすでにHive Type formatを使ってる方は知ってるかもしれません。物理的にパーティショニングを分けて管理することを検索やデータ処理にスピードを上げることができる最も簡単な方法です(例えば、2023年1月のデータが2023年フォルダに入ってるより2023年1月フォルダに管理される方が検索しやすいのと同じです)。
・hoodie.datasource.write.precombine.field : このフィールドはcombineからヒントを得てください。 結局、Hudiは後で説明するrecord keyがまるでRDBMSのPKと同じように動作します。 そのため、同じrecord key基準でupdateが発生した時、precombine fieldを基準に最新の値を判断して保存するため、Timestampあるいは時間を基準に指定することになります。
・hoodie.datasource.write.hive_style_partitioning : Hive Style partitioningはパーティショニングをするフォルダ名の構造をどのように取るかについての設定だと思えばいいと思います。 既にご存知の方もいらっしゃると思いますが、追加で説明すると、フォルダ名が一つのカラム値で動作する構造でフォルダ名が’2023’ではなく’year=2023’のような方法で保存することをHive styleと定義します。
最後に出てくる下記の3つの設定値は該当テーブルのメタ情報(スキーマ情報、位置情報など)をHive metastoreとsyncをするかどうかの設定です。AWSではGlue CatalogをHive metastoreとして使うので、イメージと同じように設定すると思います。
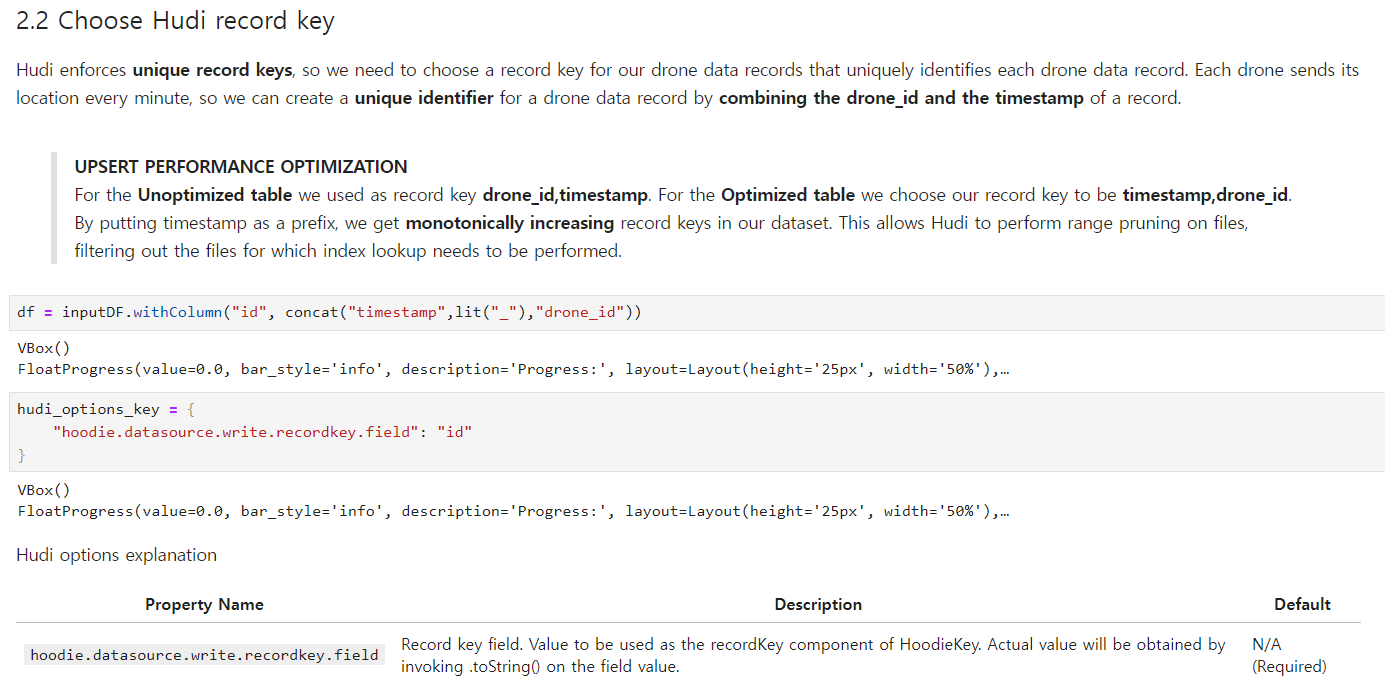
Hudi record Keyはイメージにも明示されていますが、uniqueである必要があります。これはRDBMSでよく使われる概念であるPKをS3のようなファイルシステムにも同じように適用できることを意味します(ただし、Indexポリシーをこのような方法であまりにもタイトにすると、当然、使用する時間において時間の複雑度が非常に高くなる可能性が高くなるので、適用には注意が必要です)。
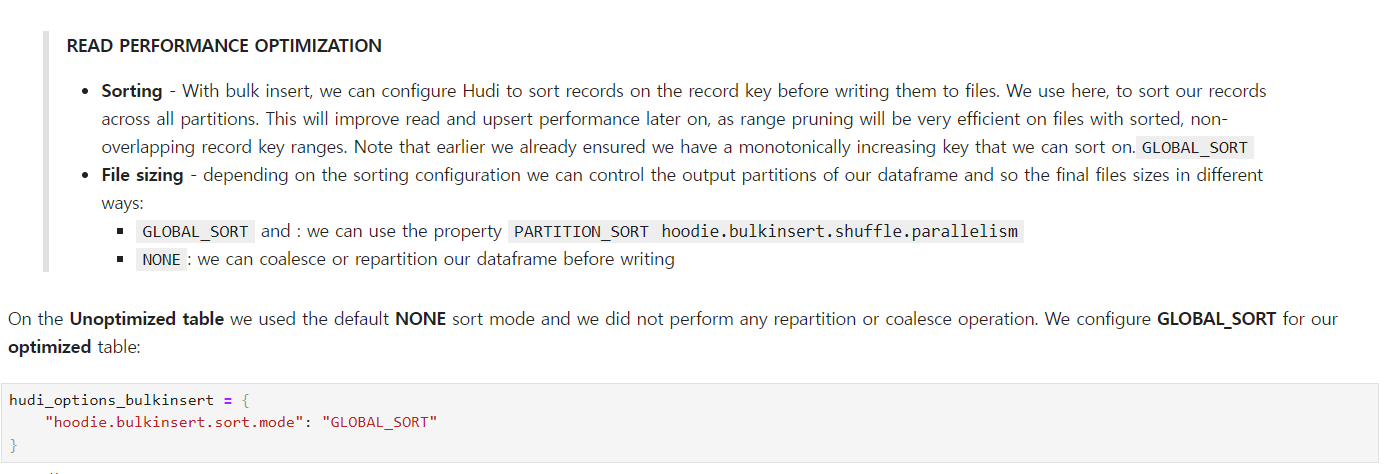
次はsortingの設定値です。Hudiではファイルを保存する時sortingを通してファイルサイズを冒頭で言及したshuffle.parallelismに基づいて調整することになり、これはファイルのサイズが一定に変更され、そのファイルのsortモードがGLOBAL(グローバル)的に発生することを意味します。
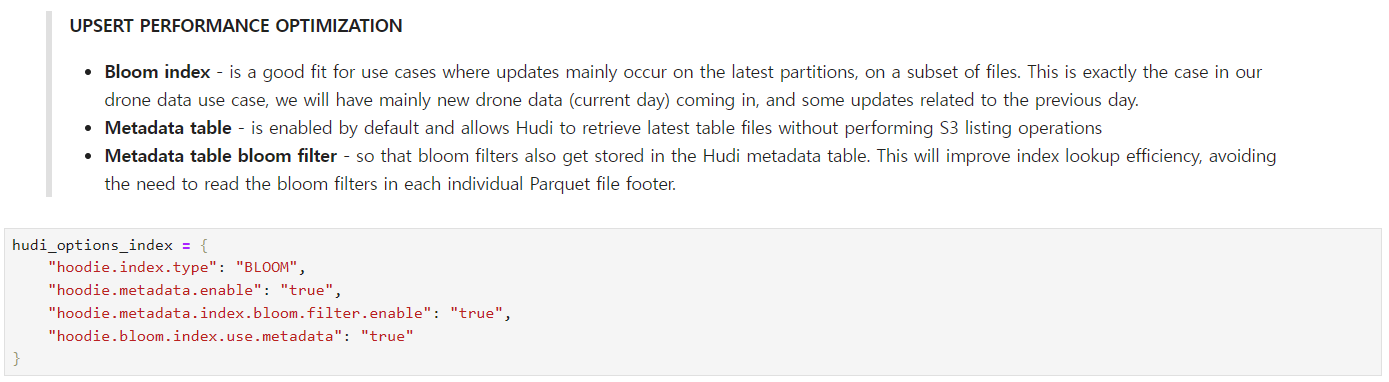
次はindexポリシーです。 この設定値は圧書で設定したrecord keyをどのような方法で管理するかについての設定です。 この部分の説明はHudi Indexingを確認してみてください。BLOOMポリシーはパーティションキーの中にあるrecord keyを独自に持っていくという意味で理解してください(例えば、2023年1月にはuniqueなrecord keyが存在しますが、ファイル全体を基準にはならないこともあります)。
・hoodie.metadata.enable : 基本的に現在のオープンソースの3つのテーブル(?)の構造はmetadataがないと使えない構造になっています。これはファイルを実際変更するのではなく、新しいファイルを作ってバージョンを管理する方法で使ってるからだと理解してください。
・hoodie.metadata.index.bloom.filter.enable : メタデータにbloom filterの値を追加してIndex基準で検索速度を上げます。これはオープンソースファイルフォーマットが実際検索をする時、全体のデータを検索するのではなく、メタデータベースで検索をするため、検索速度が速くなることができます。
・hoodie.bloom.index.use.metadata : bloomを検索する時、そのメタデータを使って検索するかどうかの設定値です(上の設定値で使用することができます)。

次はmetadata tableに追加的な情報を入力することです。 カラムに対する統計情報をメタデータに入力してこれをユーザーが検索をする時、そのメタ情報に基づいてデータをもっと飛ばすことができます(Data skipping)。
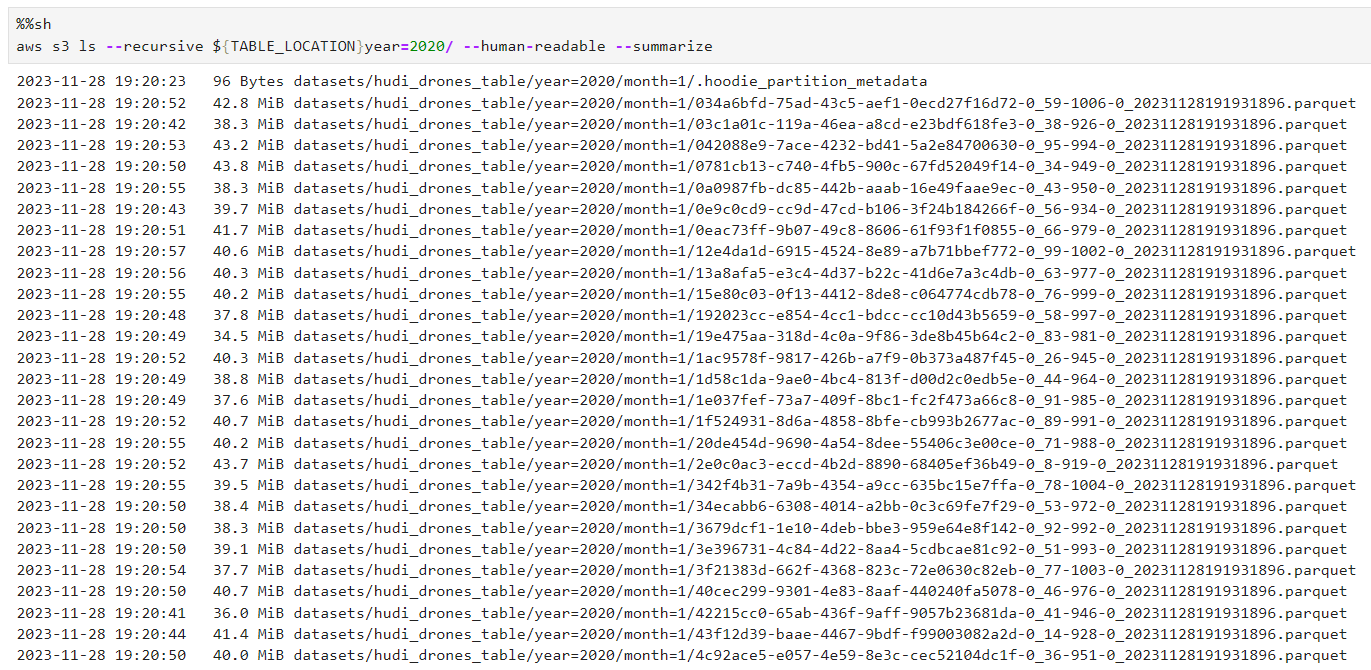
このような色んな設定値を適用したS3ファイルの結果を見てみましょう。 ご覧の通り、ファイルが約~40MBの大きさにチューニングされたことが確認できます。
もし、チューニングをしなかったら? すると、155個のファイルが~20MB程度に小さく分割される結果が出ると思います。
ファイルをどのように保存されているのでしょうか? record_key基準で5つのファイルを選んで確認してみました。
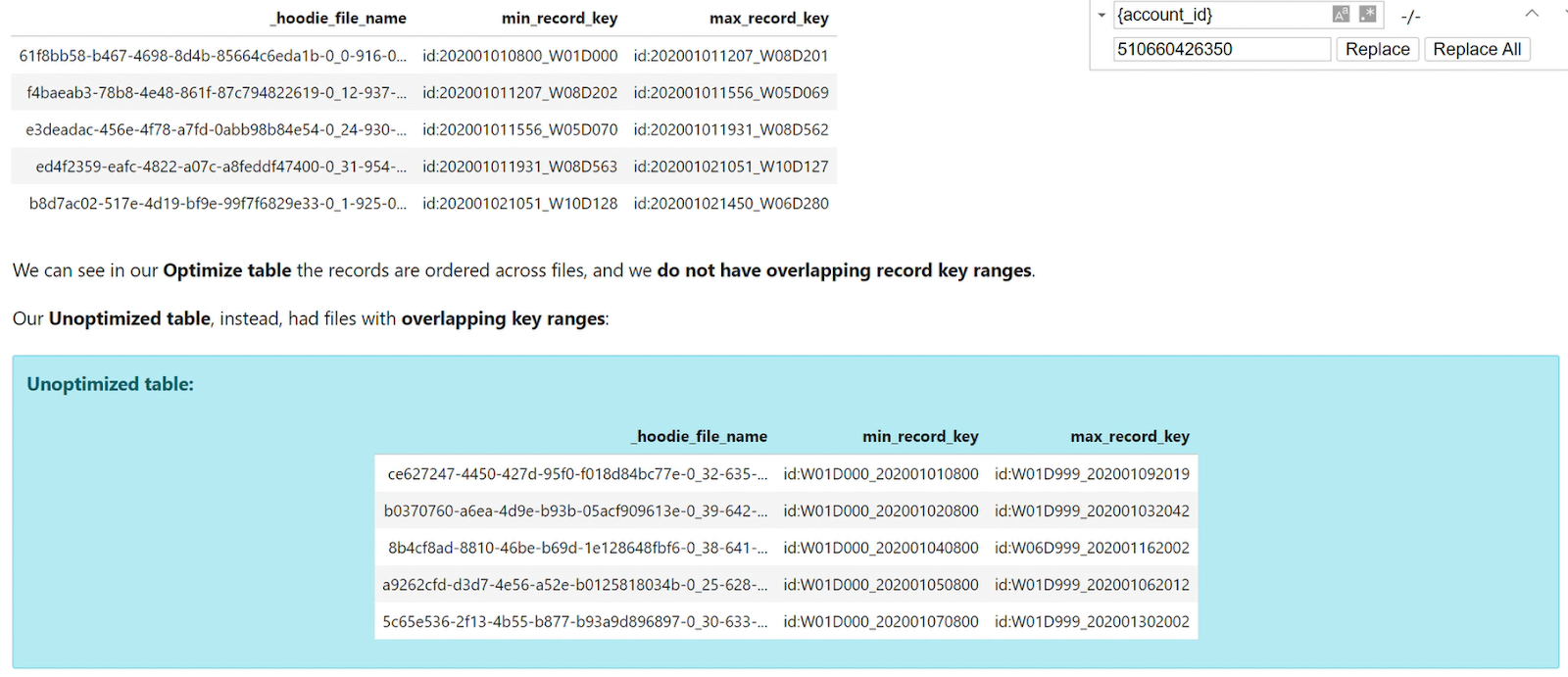
画像にも見えますが、record_keyを基準にファイルごとに重複したデータがなく、きれいにソートされていることを確認することができます。
検索性能がどう変わるか確認してみましょう。

検索はrecode_keyを基準にwhere条件節を与えた時、検索される結果が表示されます。
テスト結果7.32sくらいかかりましたし、チューニングされてないテーブルを基準には40秒かかりました。
それでは、このような結果がどのように出たのか詳しく確認してみましょう。
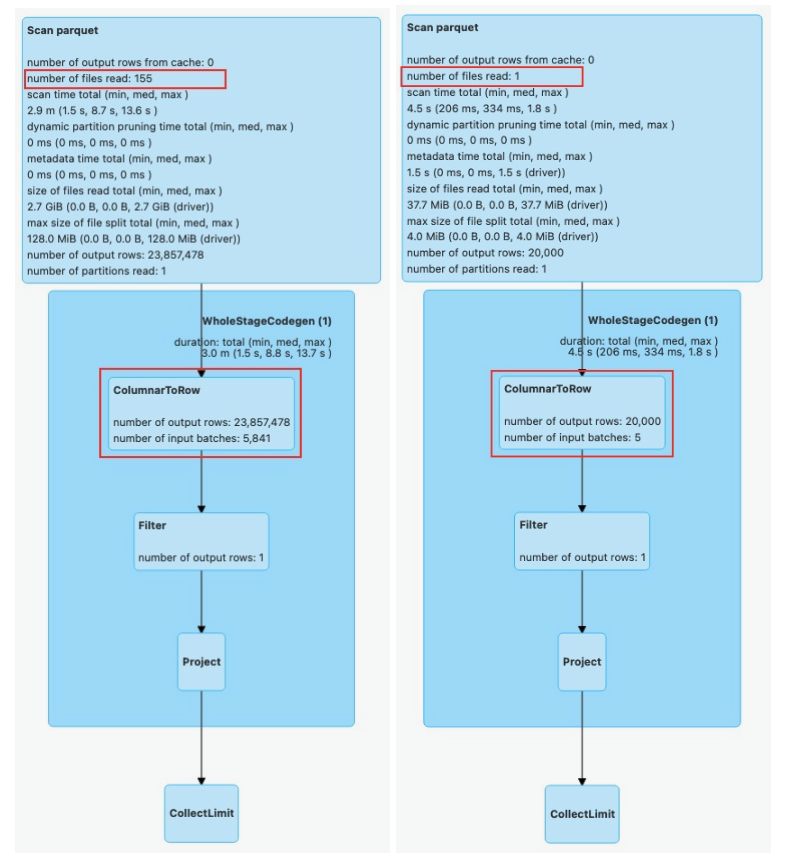
spark uiを使ってDAGで分析してみると、Scan parquet段階で読むファイルの数が155個vs1個で本当に圧倒的に減ったことが確認できます。追加的にColumnarToRow段階も一緒に減ったことが確認できます。

コネクションを使う方法は下記の通りです(例示の方法はsnowflakeでBigquery,DB2などソースによって使い方が変わることがあります。)次のコードを通してGlue環境で私たちは簡単にsnowflakeのデータソースを取得してglueで分析することができます。
Range query基準にするとどんな結果が出るでしょうか?上の基準で検索をした時、最適化されたテーブルは3~4sの時間で結果が出ましたが、最適化されてないテーブルは7sの時間がかかりました。 これはデータをスキップする過程で発生する最適化で、当然、ファイルが多くてデータのサイズが大きいほど差が大きくなります。
それでは、最後にblume indexを適用したupsertの最適化結果を確認してみましょう。
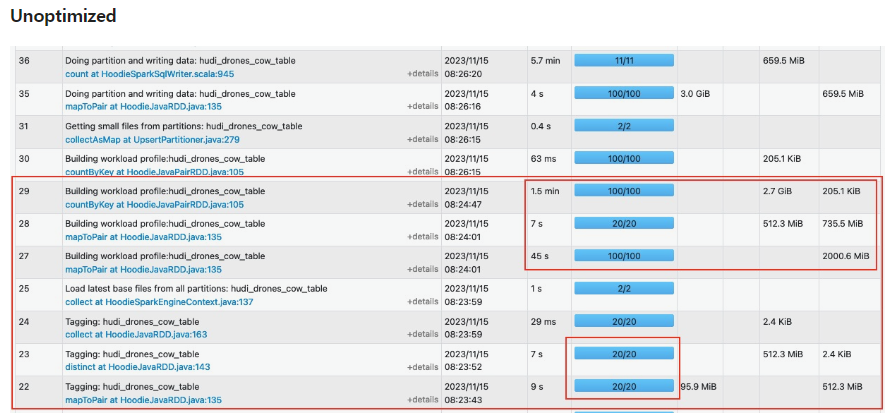
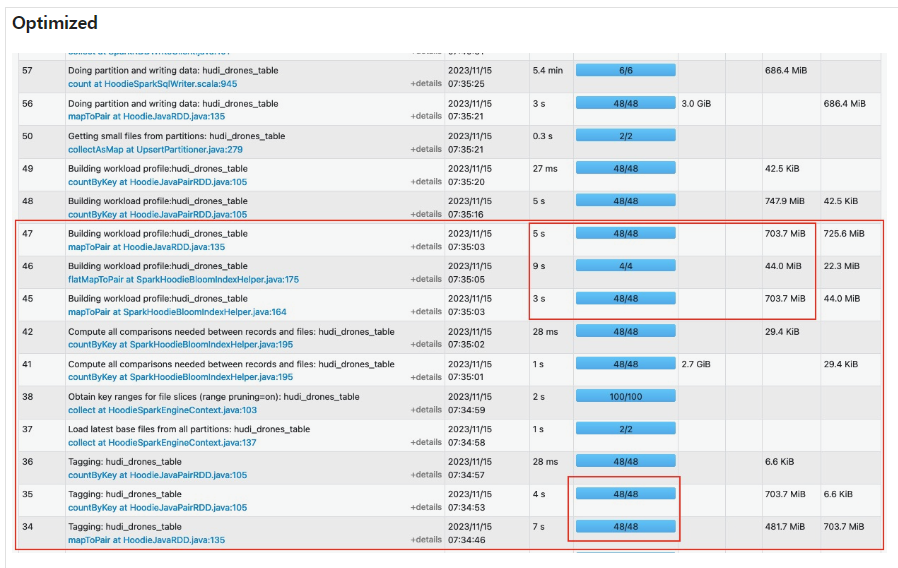
二つのspark uiを確認してみると、様々な部分で一度に使えるTaskを同時に活用することで、時間が短くなることが確認できます。実際、このような作業の場合、最適化されたテーブルは6分30秒かかった一方、最適化されてないテーブルは8分36秒以上かかることが確認できます。
セッションを終えて
今回の機会を通じてHudiの他の機能であるsorting、data skippingに対する技術を適用して、これによる効果がどの程度発生するかを確認することができました。 これは大量のデータをS3及びデータレイクを管理する上で多くの時間的工数を減らしてくれて、また、検索性能及び前処理性能の向上で成り立って非常にポジティブな効果を与えると期待しています。 また、このセッションで行ったワークショップは後日公開的にオープンするそうです。
追加情報(もし、オープンテーブルフォーマットについてもっと知りたい方は、下記のリンクを参考してください。)。
Choosing an open table format for your transactional data lake on AWS | AWS Big Data Blog (amazon.com)
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner