MEGAZONEブログ

Making your Amazon Aurora cluster more resilient
Amazon Auroraクラスタの耐障害性を高める
Pulisher : Managed & Support Center ムン・ボンギ
Description : Amazon Auroraグローバルデータベース、Amazon RDSプロキシなどの機能とAuroraクラスターのHAのベストプラクティスに関するChaltalkセッション
はじめに
Amazon Auroraデータベースは本当にパワフルで柔軟性があり、構築する際の自由度が高いようです。 実務に適用できそうなので、Amazon Auroraグローバルデータベース、Amazon RDSプロキシなどの機能とAuroraクラスターのHAに関するベストプラクティスについて聞きたかったので申し込みました。
セッションの概要紹介
Amazon Auroraクラスターの弾力性をさらに強化する方法をご紹介します。

Recover from Disruption
データベースの耐久性とは、ハードウェアの誤動作、オペレーティングシステムのクラッシュ、大規模な気象イベントなど、さまざまな障害から回復する能力を意味します。これは、サービスの中断を最小限に抑え、継続的な可用性を確保することに重点を置いています。
Dynamically Scale to Meet Demand
従来、データベースは、1年の大半がアイドル状態であっても、最大負荷を処理できるようにプロビジョニングされてきました。 これは、最も忙しい時期に備えて、年間を通じてリソースを動的に調整する機能です。
Continue Operating Even When Impaired
データベースが一時的に制限された時にもサービスを持続できる耐久性を意味します。
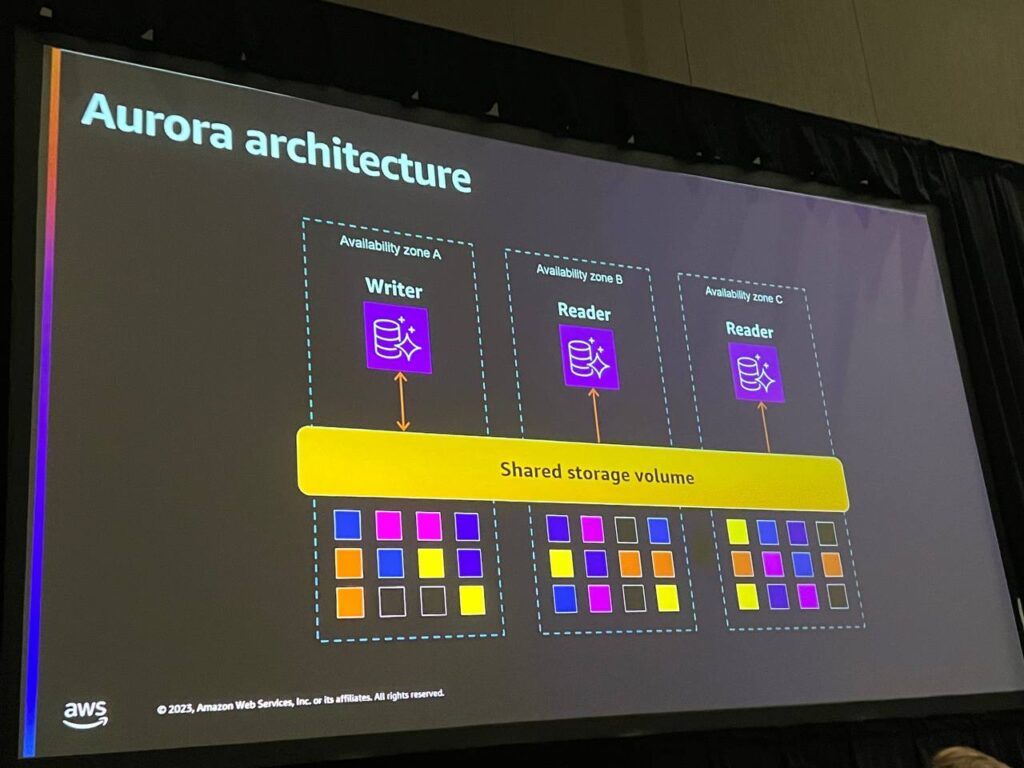
Auroraアーキテクチャの共有ストレージボリュームは、データベースがストレージレイヤーにデータを記録する際、そのデータはデフォルトで3つのAZに6回複製されます。この機能は自動的に有効化され、ユーザーが有効化または無効にすることはできません。
1つのデータベースインスタンスはストレージ層から分離され、クラスターに作成者と最大15個のリーダーを追加することができます。すべてのインスタンスは同じストレージを指し示します。 したがって、Auroraではレプリケーションを追加してもデータコストが増加せず、コストを節約することができます。 また、AZ障害が発生した場合、Auroraはフェイルオーバー(Failover)をサポートします。

Point-in-Time Restore
Auroraクラスターを設定する際に一定期間の自動バックアップを選択し、選択した期間内に特定の時点への復元が可能です。 また、新しいクラスターを作成してデータを復旧することもできます。
Snapshots
手動で生成されるデータのコピーで、スナップショットを作成して検証が必要な場合に活用されます。スナップショットは保管期間に柔軟性を提供しますが、長期保存には好まれません。
AWS Backup
すべてのサービスに対する統合的なバックアップ管理を希望する場合、AWS Backupを活用することができます。
Amazon S3
AuroraクラスターからデータをAmazon S3にエクスポートする機能で、クラスター全体、一部のクラスター、または特定のテーブルをエクスポートするなど、多様な方法を提供します。

AuroraクラスターからエクスポートするデータはAmazon S3に移動し、Parquet(PK)形式で保存されます。Amazon S3の指定された場所に保存され、S3バケット内のフォルダ構造で整理されます。S3に保存されたデータは、必要に応じてAthena、Redshift、OpenSearchなどのサービスで活用可能です。Athenaを使用してサーバーレスSQLクエリでデータを分析したり、Redshiftを通じてデータウェアハウスで複雑な分析を行うことができます。
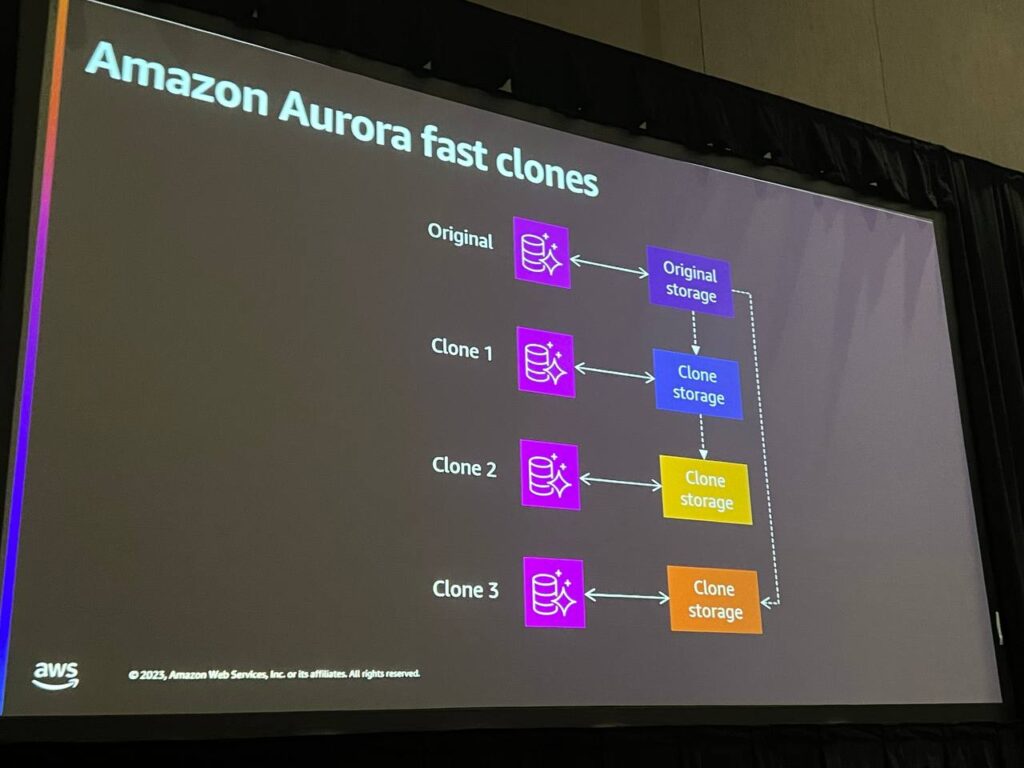
Aurora Fast Clonesは、データベースのクローンを素早く作成する機能です。Fast Clonesを使用すると、元のデータベースのスナップショットに基づいて迅速にクローンを作成することができます。これにより、特定のチームやユーザーに制限されたデータを持つクローンを生成することができます。機密情報はクローンを作成する前に匿名化してセキュリティを維持し、この作業は本番インスタンスに影響を与えません。 Fast Clonesは、データを迅速に複製し、高性能でクローンを作成し、便利な機能を提供します。

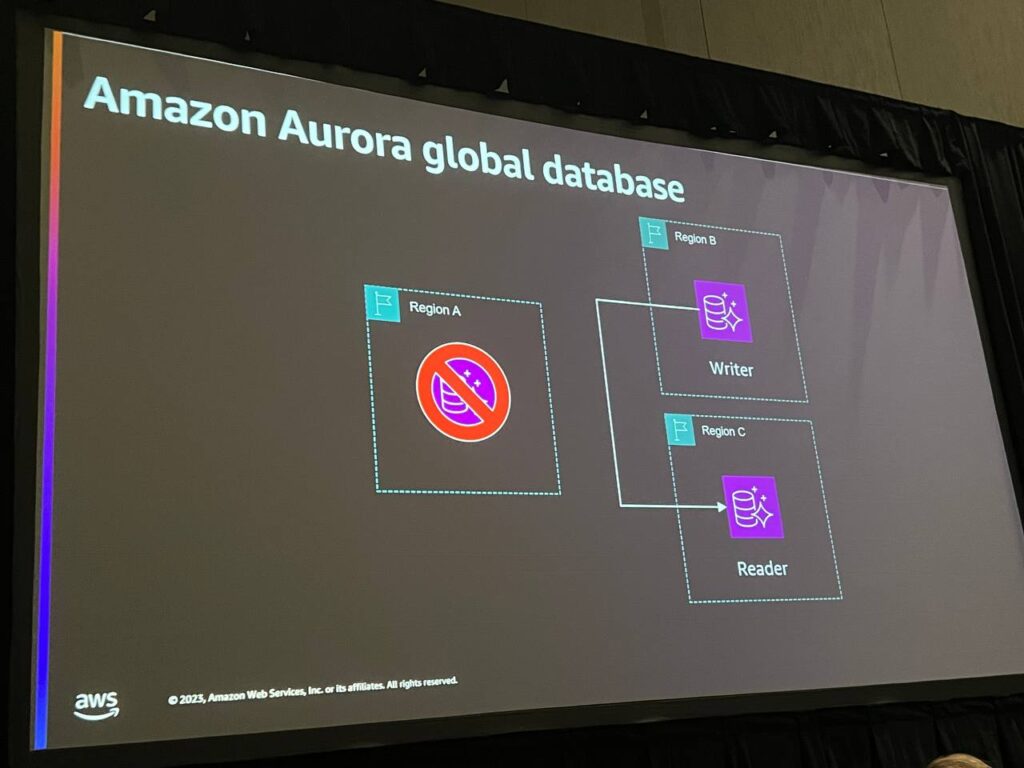
Aurora Global Databaseは、Amazon Auroraデータベースのグローバルレプリケーションソリューションで、複数のリージョンで同じデータベースを使用できるようにします。これは地域間のデータ複製を自動的に管理し、書き込み作業は基本リージョンで行われ、読み取り作業はグローバルデータベースクラスター内の他のリージョンで行われます。これにより、グローバル規模のスケーラビリティと可用性を提供します。
Global Databaseを使用すると、お客様はリージョン間の読み取りレプリケーションにより、遅延時間を最小化し、データの安定性と可用性を強化することができます。


Aurora Serverless v2は、Amazon Auroraデータベースのサーバーレス展開モデルの次のバージョンです。 このモデルは、データベースリソースの自動拡張と縮小を可能にし、トラフィックの変動に応じて可変的に対応することができます。
Aurora Serverless v2は、特にビジネスのニーズに応じて自動的にスループットを調整しながら、ユーザーにコスト削減と運用の利便性を提供します。また、新しいチューニング機能と詳細な制御オプションを導入し、データベースのパフォーマンスを最適化することができます。
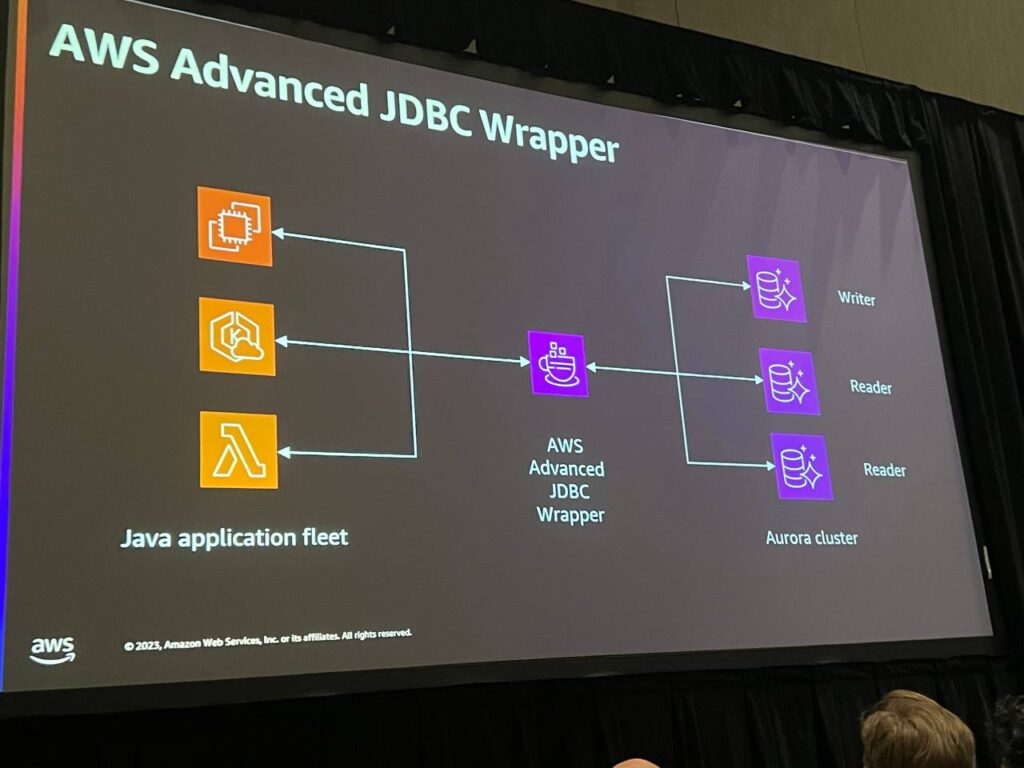
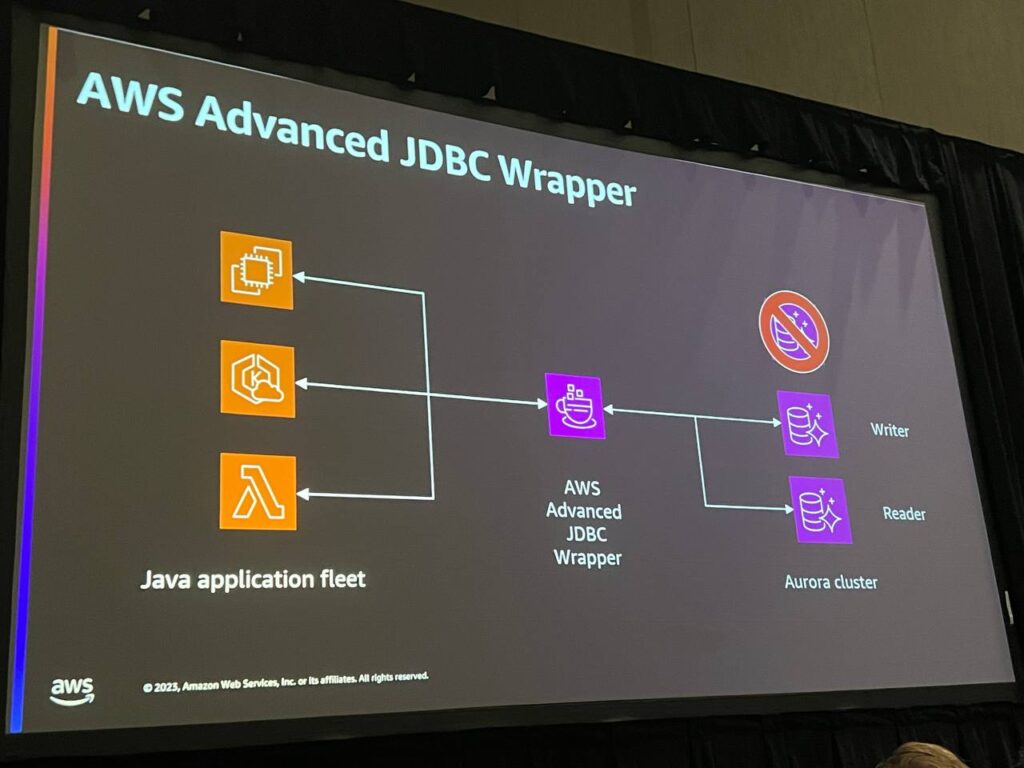
JDBC Wrapperは、JDBCを使用してデータベースと対話するJavaアプリケーションで特別な動作を簡単に実装するのに役立ちます。JDBC Wrapperは主に性能最適化、セキュリティ強化、コード簡素化など、様々な目的に使用することができます。
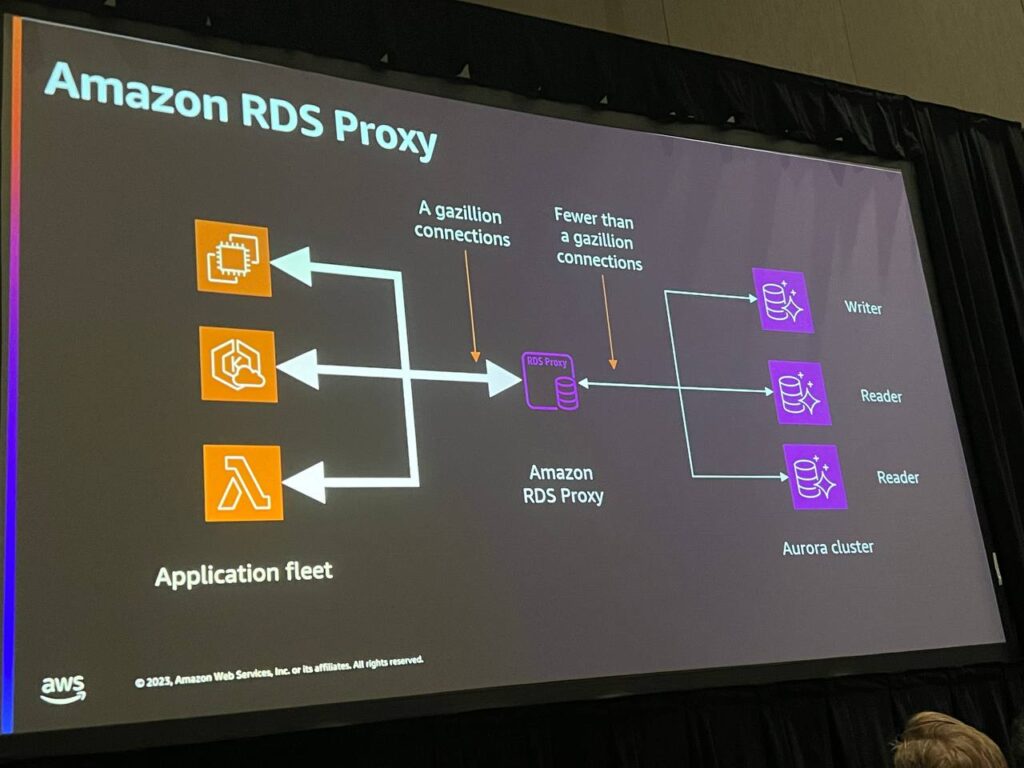
Amazon RDS Proxyは、データベースアプリケーションとAmazon RDSインスタンス間の接続を管理してパフォーマンスを最適化し、障害に備えて可用性を向上させます。RDS Proxyは、クライアントアプリケーションが複数の接続を効率的に管理し、データベースバックエンドへの安定的な接続を提供し、読み書きトラフィックを分散してデータベースの負荷を軽減します。
セッションを終えて
このセッションはChalk Talkなので、上記の内容を説明し、自由に質問して答えてくれるセッションでした。Amazon Aurora clusterと関連した機能について詳しく説明してくれて、その機能を適用するときに重点的に考えなければならないこと、そして現在構築された環境を補完することができる方法についての説明を聞くことができ、今後Aurora RDSの導入及びグローバルサービスのAurora RDS構築をするときに適用することができそうです。
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner