MEGAZONEブログ

Advanced serverless workflow patterns and best practices
高度なサーバーレスワークフローのパターンとベストプラクティス
Pulisher : Cloud Technology Center キム・ビョンジュ
Description : ワークフローの構築とコスト最適化のためのアーキテクチャのベストプラクティスと反復可能なパターンについて紹介したセッション
はじめに
データエンジニアとしてWorkflowサービスを調べて学習することは基本的な内容になっています。最近はAirflowがかなり有名で、ほとんどの会社でAirflowをかなり積極的に活用しています。
AWSではこのようなAirflowサービスを提供するためMWAAを提供しています。しかし、workflowで選択できるサーバーレスオプションであり、それなりに安いStep Functionの使い方を知りたいと思い、このセッションを申し込みました。
セッションの概要紹介
セッションでは、Step Functionを使ってApplicationを開発する方法を紹介し、そのメリットについても紹介します。そして、このセッションの進行役はServerlesspressoをStep Functionをメインに構築した主なメンバーでもあります。
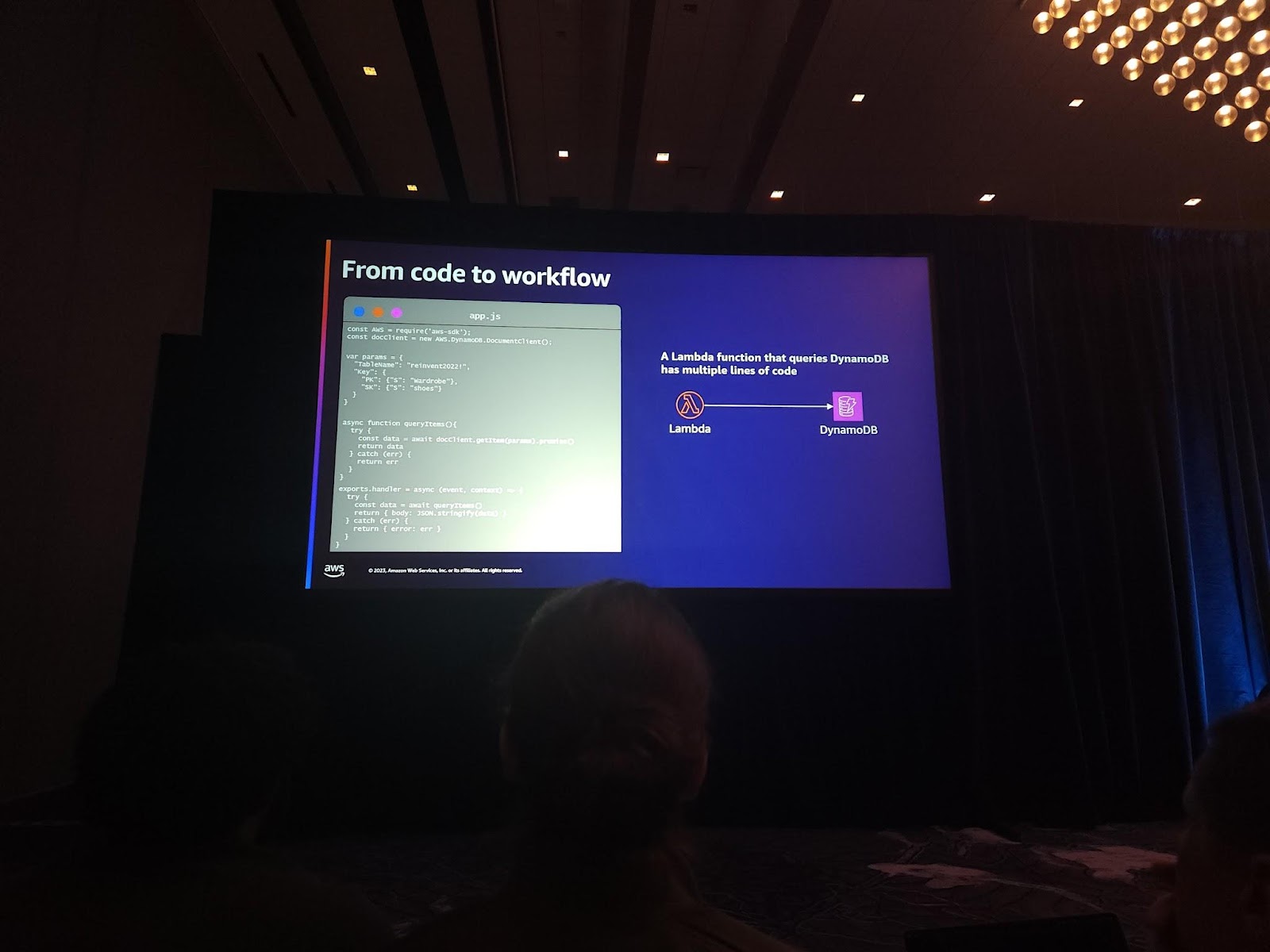
私がStep Functionを開発する時使う理由は何でしょうか?もし、顧客がDynamo DBにLambda Functionを使ってitemを取得するとします。 最初はAWS SDKを宣言します。 その後、DynamoDB用Doc Clientを取得します。 そして、テーブルから取得するデータをクエリを取得してtry/catch構文を作成します。 そして、最後にその完了情報を渡したり、catch情報を返すように作成します。20行くらいでこれをすることができますね…じゃあ、Step Functionではどうでしょうか?

ブロック一つで解決します。本当に簡単ですね。 もし、例外処理を入れたい場合は、それも可能です。Step Functionでは、そのタスクの成功や失敗に関するメッセージを保存して提供します。そして、色んなサーバーレスサービスと連携が可能なので、これはとても強力な機能です。様々なサービスを連動してログを一度に見るのは本当に難しいことだからです。

2番目の事例を確認してみましょう。API Gatewayと連携してLambda関数を作成すると仮定してみましょう。一つのLambdaを連結してDynamoDBに連動する作業はシンプルかもしれませんが、Lambdaコードの中で/GET, /POSTに対するルーティングも必要で、権限や機能が複雑になります。 時には一つのコードで管理するより管理ポイントが多くなり、コストが高くなることもあります。
もちろん、次のステップで提供するLambdaを/GETラムダ、/POSTラムダなどで分離するのも良い方法です。

しかし、Step Functionを使うとどう変わるのでしょうか?ラムダを通さずにStep Functionで直接APIを判断して必要な機能でStep Functionの機能を使ってDynamoDBにデータを消去、変更、挿入、インポートなど様々な機能をすることができます。

私たちがServerlesspressoを構築した時も同じ問題に直面しました。 最初はそれぞれの注文をLambda関数を介して動作するようにしました。 しかし、アプリケーションが進化し、様々な複雑な作業が追加され、エラーを見つけるのが難しくなったり、様々な注文が複数のサービスを介しているため、デバッグが難しくなりました。 したがって、私たちはこのような経験をより良く解決するためにStep Functionをより良く活用するように変更し、パフォーマンスは以前より良くなりました。

私たちはExpressを使用し、これによってアプリケーションの注文手続きがより速くなりました。 また、ExpressではSynchronous方式で呼び出すことができます。つまり、Step Functionを通じてAPI Gatewayに結果を返すことができるという点があります。

そして、Step FunctionのStandardタイプは状態遷移によって価格を設定する一方、Express Workloadはメモリと動作時間に比例して価格が課金されるため、価格設定に応じた結果が出ることがあります。Express Workloadのメモリ使用コストはinput/outputサイズに影響を受けます。

実際にテストで設計したWorkflowを1,000回くらいそれぞれのタイプで回してみたところ、Standard 420$、Express 12.77$ が出たことを確認することができました(本当に差が大きいですね)。ほとんどの workloadは5分以内に解決されるので、ほとんどのお客様はStep Function Expressを使うことができます。

それにもかかわらず、私たちがStandardタイプを選択しなければならない理由は何でしょうか? 当然のことながら、5分以上のワークロードが回る場合には選択する必要があり、Input/output値が大きければ、よりコスト効率的に使用することができます。
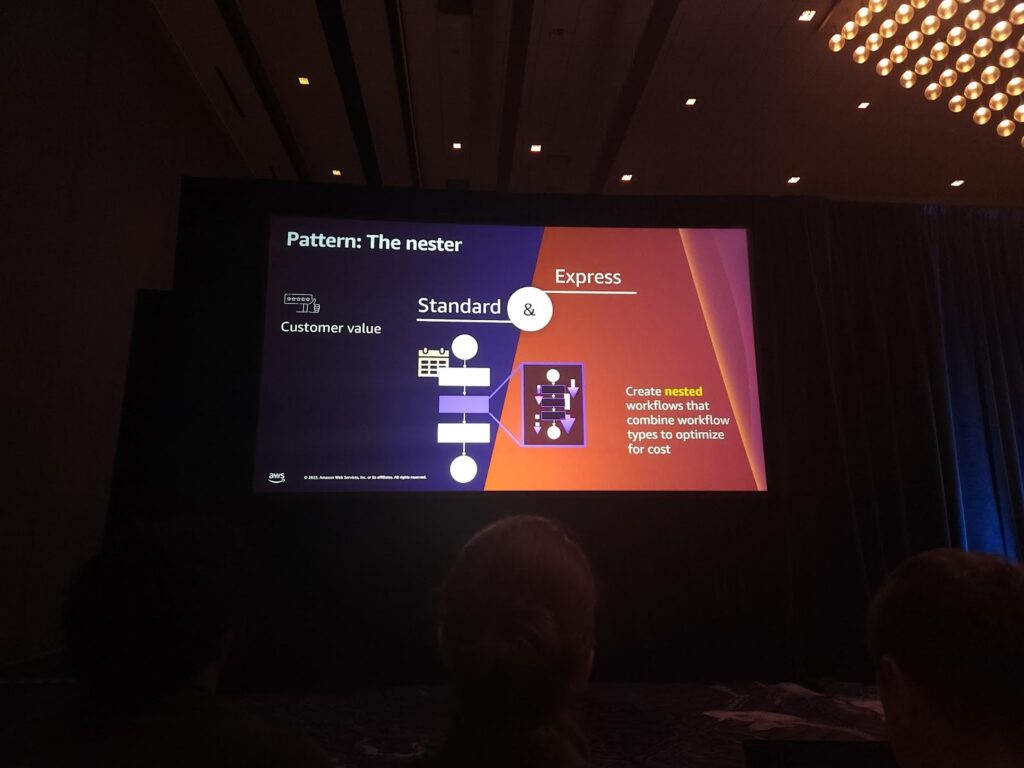
そして、Standardタイプのコストを削減する方法は何でしょうか? まず、最も簡単に試せるのは、一部のワークロードをExpressワークロードを使用して切り替えてみたり、状態遷移中の待ち時間を追加して状態遷移の回数を減らすことも大きな助けになります!
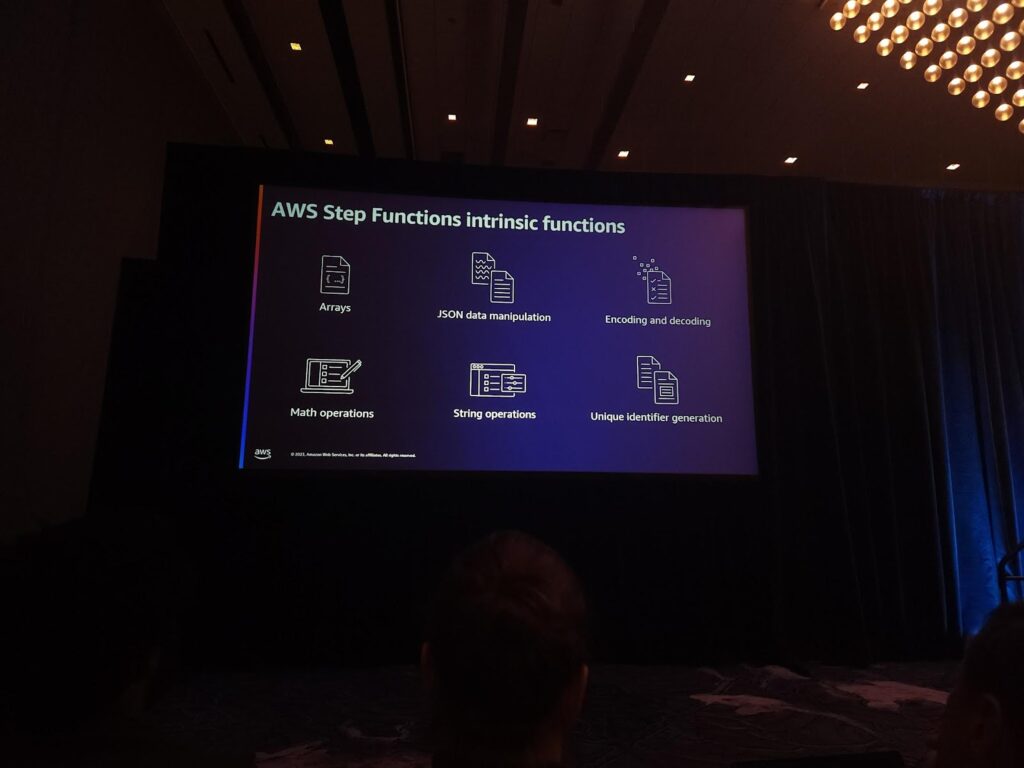
そして、Step Functionが提供する様々な追加機能を使ってコストと時間を節約してください。

例としては、固有IDを作る必要がある状況を予想してみます。一般的にLambdaを連結してコードを書いてライブラリをドラッグしてきます。 しかし、Intrinsic functionを使って処理すると、実行に遅延がなくなり(ラムダコールドスタートなど)、呼び出しにコストがかからず、コードを少なく書くことができます。

また、Standard Workflowでは、call backパターンを使用することができます。 waitを通して、もちろんポーリングループを制御するのは簡単な方法ですが。コストや時間的に我々の要件に合わない場合があります。 call backパターンを導入してみましょう。よりコストを節約することができます!

発表を終える前に、私が紹介しきれなかった新機能があるかもしれません。2週間前にリリースした失敗した時点からやり直すRedrive、次はHTTP state機能です。Step Functionから直接呼び出すことができます。すべてのテストのために全体のワークロードを回さなくても個別にTaste可能なTest API機能、そしてBedrockと連動する機能が追加されました!
セッションを終えて
Step Functionは本当に様々な機能がリリースされました。サーバーレスは本当に難しいテーマであり、あまりにも多くのサービスが使われ、連動も難しく、これを一度にまとめて動作させるWorkflowを構築すること、そしてそのようなログも一度にまとめて見るのは本当に難しい作業です。もし、様々なサーバーレスサービスを使ってアプリケーションを構築したいなら、まずはStep Functionから始めてみてください!
この記事の読者はこんな記事も読んでいます
-
 Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する)
Compute re:Invent 2023Apple on AWS: Managing dev environments on Amazon EC2 Mac instances(Apple on AWS:Amazon EC2 Macインスタンスで開発環境を管理する) -
 Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化)
Compute re:Invent 2023Optimizing for cost and performance with AWS App Runner(AWS App Runnerによるコストとパフォーマンスの最適化) -
 Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner
Partner Enablement re:Invent 2023Migration and modernization: Become your customer’s strategic partner